


本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
PyTorchとは?ディープラーニングの基礎から理解する

ディープラーニングの基礎を理解する前に、まずPyTorchとは何かを解説します。PyTorchは、ディープラーニングのためのオープンソースの機械学習ライブラリであり、柔軟性とパフォーマンスの両方を提供します。
Torchの意味とPyTorchの基本概念
Torchとは、PyTorchの前身であり、数値計算ライブラリの一環として開発されました。基本的な用語や概念についても触れながら、PyTorchの基本的な使い方を紹介します。
PyTorchの基本概念:テンソル、モデル、そして学習の仕組み
PyTorchの中心となる要素であるテンソルやモデルについて以下に解説します。
- テンソル(Tensor)
PyTorchでのデータの基本単位
多次元の配列であり、数値データを効率的に表現し、数学的な操作やニューラルネットワークの入力として使用されます。
- モデル(Model)
ディープラーニングモデルの構築に使用される抽象的な概念。
層(Layers)や活性化関数などを組み合わせて定義され、テンソルを受け取り、処理を行う機能を持ちます。
- 学習の仕組み
ニューラルネットワークがデータから学習する仕組み
訓練データを用いてモデルのパラメータを調整し、損失関数を最小化するように最適化します。バックプロパゲーションと呼ばれる手法が用いられ、モデルがデータに適応します。
バックプロパゲーションとは、ニューラルネットワークの学習において、偏微分を用いて損失関数と勾配の計算を行い、その情報を出力側から逆方向に返すことで、誤差を最小化するためのアルゴリズムです。
- 順伝播と逆伝播
学習の主要なプロセス
順伝播では、モデルがデータを受け取り、予測を行います。これに対し逆伝播では、損失を最小化するようにパラメータを調整します。これを繰り返すことでモデルがデータに適応し学習が進みます。
- オプティマイザと損失関数
モデルの学習を制御する要素
オプティマイザはモデルのパラメータを更新するアルゴリズムを提供し、損失関数はモデルの予測と実際のデータの差を測定し、最小化の対象となります。 これらの要素が組み合わさり、PyTorchは柔軟かつ強力なディープラーニングフレームワークを構築する基礎となっています。
実践的なPyTorch:画像分類から手書き文字認識までの応用
ディープラーニングの魅力を体験するために、PyTorchを使用した簡単な画像分類のサンプルコードを紹介します。以下は、手書き数字認識の例です。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# データの読み込みと前処理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_data = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
# シンプルな畳み込みニューラルネットワークの定義
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.fc = nn.Linear(28 * 28 * 32, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# モデルの構築
model = CNN()
# 損失関数とオプティマイザの定義
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習
for epoch in range(5): # 5エポックだけ学習する例
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 学習後のモデルを利用して手書き数字認識が可能になります。
PyTorchで体験するディープラーニングの魅力:サンプルコード解説
このサンプルコードは、教育的な目的を持ち、手書き数字認識のためのシンプルな畳み込みニューラルネットワークを構築し、MNISTデータセットを用いて学習するものです。以下にコードの主なポイントを説明します。
1. データの読み込みと前処理
transformsモジュールを使用して、データをPyTorchで扱いやすい形式に変換します。MNISTデータセットは手書き数字の画像と対応するラベルから構成されています。
2. ネットワークの定義
シンプルな畳み込みニューラルネットワーク(CNN)を定義します。このネットワークは畳み込み層、ReLU活性化関数、全結合層から構成されています。
3. 損失関数とオプティマイザの定義
交差エントロピー損失を使用し、Adamオプティマイザでモデルを最適化します。
4. 学習
データローダーからミニバッチを取り出し、モデルに入力して予測を行います。損失を計算し、逆伝播とオプティマイザの更新を行います。これを複数エポック繰り返すことで学習が進みます。
トリックとテクニック:PyTorchを使った効果的なモデルの構築
ディープラーニングモデルを構築する際に、PyTorchを活用して効果的で効率的なモデルを実現するためのトリックとテクニックがあります。以下に、いくつかの重要な要素に焦点を当てながら説明します。
1. 転移学習の利用
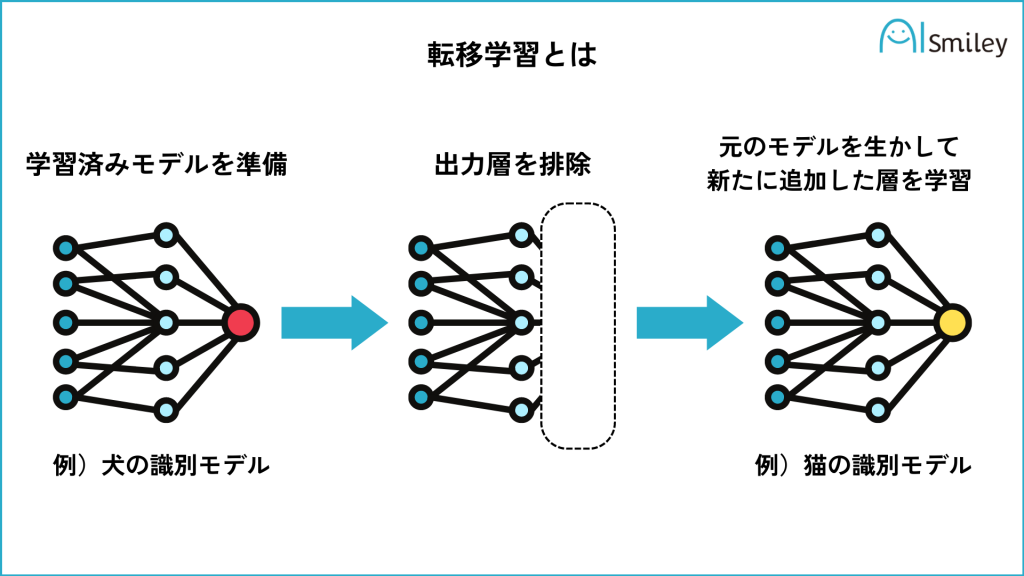 転移学習は、事前に学習されたモデルの知識を新しいタスクに適用する手法です。
転移学習は、事前に学習されたモデルの知識を新しいタスクに適用する手法です。
例えば、大規模なデータセットで学習済みの画像分類モデルを取得し、そのモデルの一部を新しいモデルに組み込むことで、新しいタスクに対してより高い性能を発揮することができます。
2. データ拡張
データ拡張は、限られたトレーニングデータをより多くのバリエーションで学習させるための手法です。例えば、画像データに対してはランダムな回転、ズーム、反転などの変換を適用し、モデルがより多くのパターンを学習できるようにします。
3. ドロップアウト
ドロップアウトは、ネットワークの学習中にランダムにノードを無効にする手法で、過学習を防ぐのに役立ちます。これにより、モデルが特定のパターンに過剰に適応することを防ぎ、一般的な特徴をより効果的に学習できます。
4. 学習率の調整
学習率はモデルのパラメータを更新する際のステップの大きさを示します。適切な学習率を選択することは、モデルの収束速度や最終的な性能に影響を与えます。学習率の調整は、トレーニングの進捗に応じて動的に変更されることがあります。
5. 畳み込み層の適切な設計
画像認識などのタスクにおいては、畳み込み層の設計が重要です。適切なフィルターサイズ、ストライド、プーリングなどを選択することで、モデルは画像の階層的な特徴を効果的に捉えることができます。
これらのトリックとテクニックを組み合わせて利用することで、PyTorchを使用して効果的なディープラーニングモデルを構築することができます。実践的な例やコードを交えながら、これらの手法の使い方を理解していきましょう。
PyTorch応用事例:自然言語処理から転移学習までの実例紹介
PyTorchを用いた応用事例として、自然言語処理(NLP)に焦点を当て、転移学習の手法を使用する実例を紹介します。これにより、一般的なNLPタスクにおいても効果的なモデルの構築が可能であることを示します。
自然言語処理の基礎

自然言語処理は、機械が自然言語を理解し、処理するための技術です。テキストデータから情報を抽出し、意味を理解することで、様々なタスクに適用されます。具体的なタスクとしては、文書分類、感情分析、機械翻訳などがあります。
転移学習の活用
転移学習は、あるタスクで学習されたモデルを、異なるタスクに適用する手法です。NLPにおいては、大規模な言語モデル(例: BERT、GPT)で学習された知識を転移して、少量のラベル付きデータで新しいタスクに適用することが一般的です。
実例:感情分析の転移学習
例として、感情分析(テキストから感情を判定するタスク)に焦点を当てた実例を紹介します。感情分析には日本語のテキストを対象にし、事前学習済みの日本語BERTモデルを使用します。
データの準備 : テキストデータとその感情ラベルを用意します。例えば、映画レビューコーパスなどが利用できます。
トークナイザーとエンコーディング : BERTモデルに適した形式にテキストデータを変換します。トークン化やエンコーディングは、事前学習済みのBERTモデルが期待する形式で行います。
モデルの定義とオプティマイザ : BERTベースの感情分析モデルを定義し、適切なオプティマイザを選択します。
学習 : ラベル付きデータを用いてモデルを学習させます。適切な損失関数や評価指標を選び、エポック数やバッチサイズなどのハイパーパラメータを調整します。
この実例では、大規模な言語モデルの事前学習済み知識を利用して、感情分析タスクにおいて高い性能を発揮することが期待されます。


『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
記事全体のまとめとして、PyTorchの基礎から実践までを網羅しました。この記事を入門編として、pytorchを用いてさまざまな勉強に取り組んでみましょう!
参考文献





