

13章ではPandasのDataFrameの結合方法である『内部結合・外部結合・左結合・右結合』について解説します。
また、DataFrameの結合に使う『pd.concat()関数』『pd.merge()関数』『joinメソッド』について解説します。
本記事を読めばDataFrameの結合について体系的に理解することができます。
ぜひ最後まで読んでいってください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
データのさまざまな結合方法
データの結合とは・キーとは
2つ以上の表形式のデータを基に1つの表を生成することを『結合』と言います。
また、結合における『キー』とは、結合の軸となる列のことです。
例えばキーを『name』列として2つの表を内部結合すると以下の図のようになります。
なお、内部結合とは元データに共通するデータのみを取り出して結合する結合方法です。後程詳しく説明します。
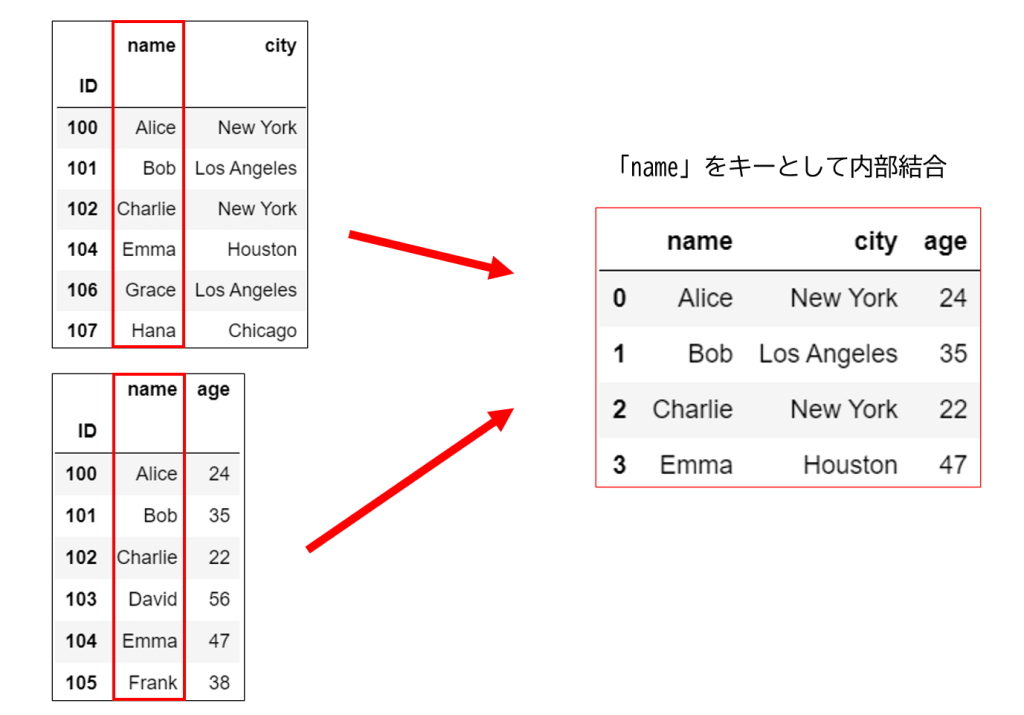
データの結合にはいくつかの方法があり、それぞれを状況に応じて使い分ける必要があります。
まずはそれぞれの結合方法について図とともに理解していきましょう。
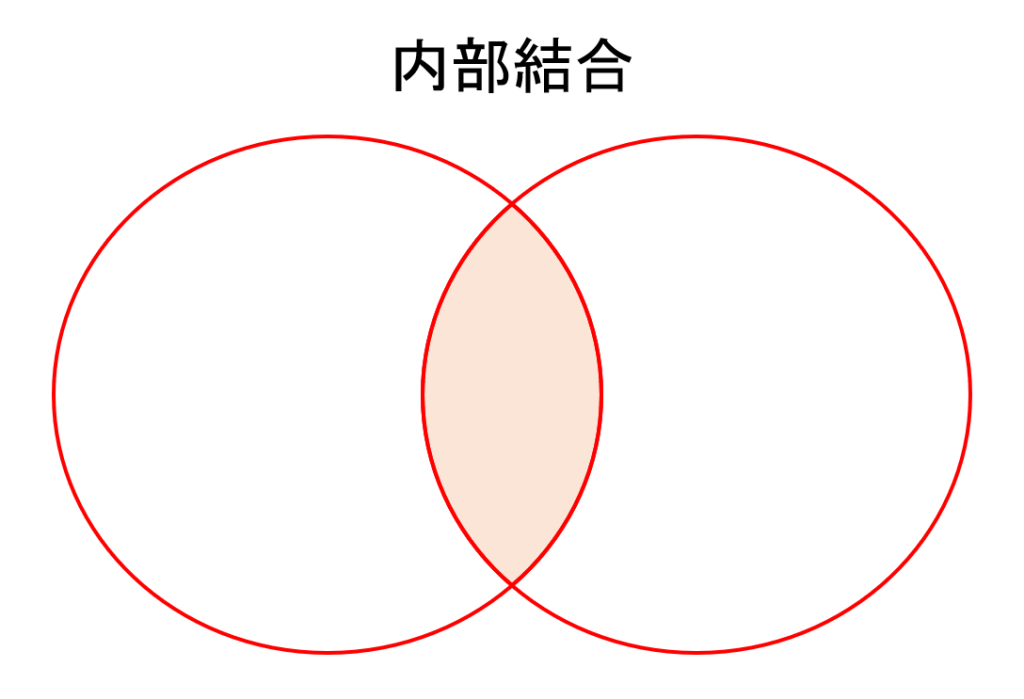
内部結合
『内部結合』は元データの両方に共通のキーの値があるときに結合します。
先ほどの例ではキーを「name」列として内部結合を行いました。
このとき、両方の「name」列に存在する「Alice, Bob, Charlie, Emma」の4つのデータのみが取り出されていることが分かると思います。
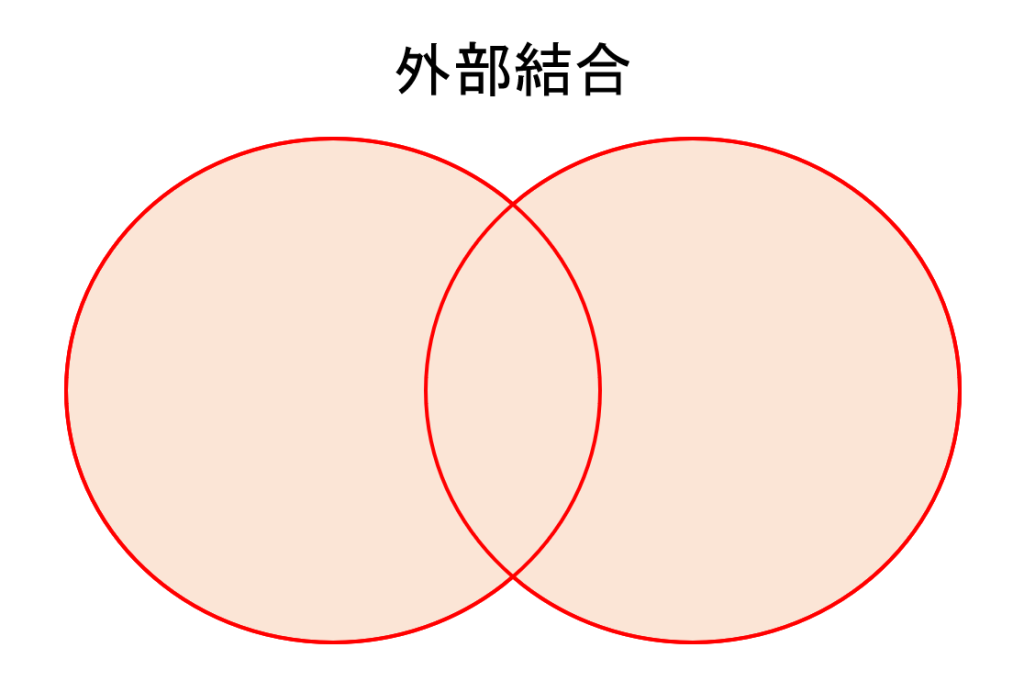
外部結合(全結合)
『外部結合』は元データの少なくとも一方にキーの値があるときに結合します。
先ほどの例で外部結合を行った場合、以下のような結果になります。
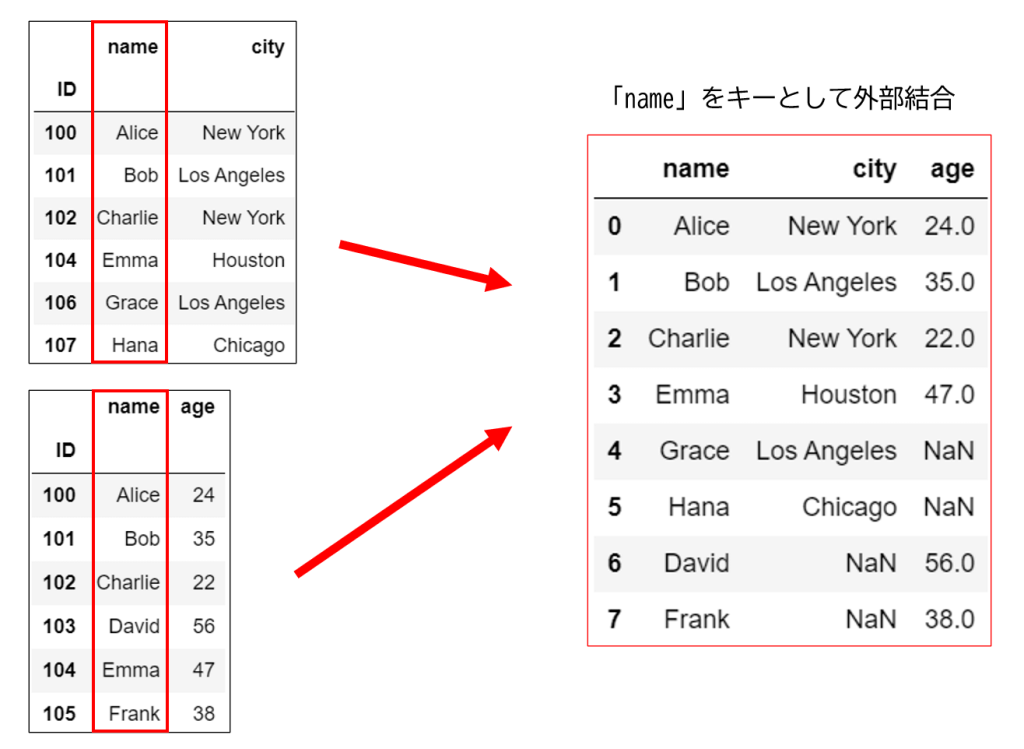
いずれかの「name」列に存在する、「Alice, Bob, Charlie, Emma, Grace, Hana, David, Frank」の8つのデータが取り出されていることが分かると思います。
なお、値が存在しない要素はNaNで置き換えられます。
また、「age」列がfloat型になってしまっているのはNaNの影響です。
左結合
『左結合』は左側のデータにあるキーの値をもとに結合します。
ここで、今回紹介するデータの結合における『左』は引数として先に指定されたデータを表すこととします。
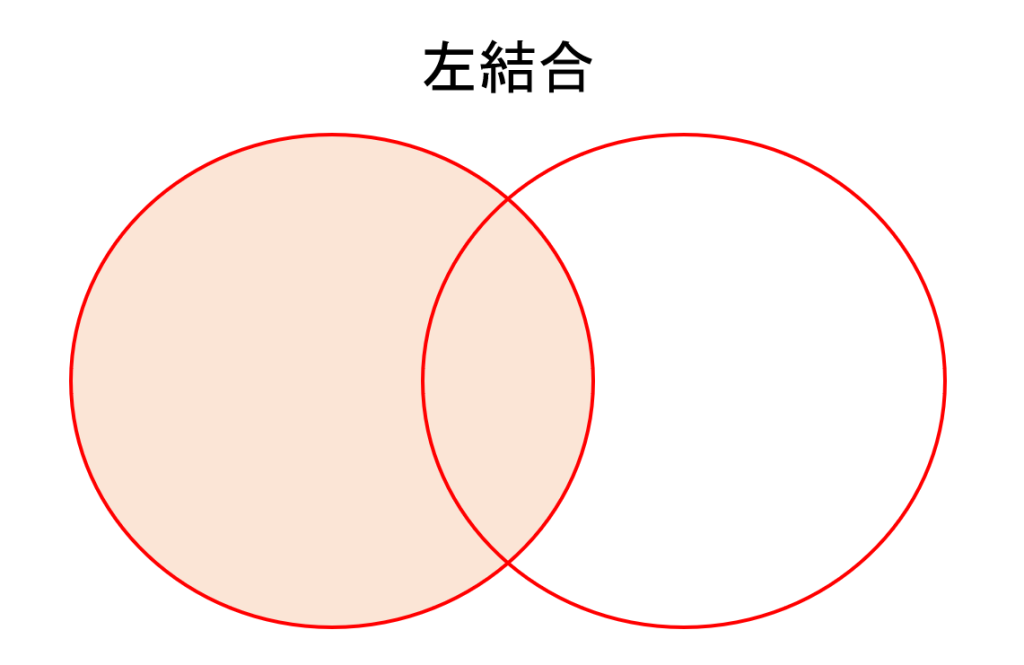
先ほどの例で左結合を行うと以下のような結果が得られます。
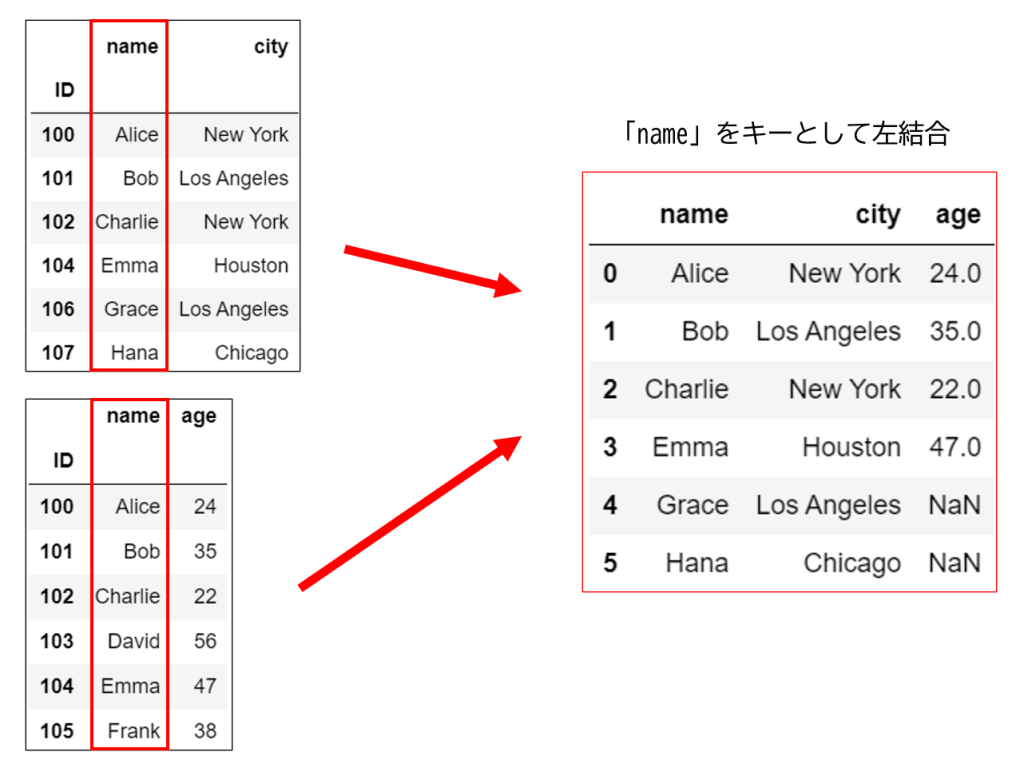
上の図において「左のデータ」は結合前の上側のデータを指します。
左のデータの「name」列にある「Alice, Bob, Charlie, Emma, Grace, Hana」の6つのデータが取り出されていることが分かります。
右結合
『右結合』は右側のデータにあるキーの値をもとに結合します。
ここで、今回紹介するデータの結合における『右』は引数として後に指定されたデータを表すこととします。
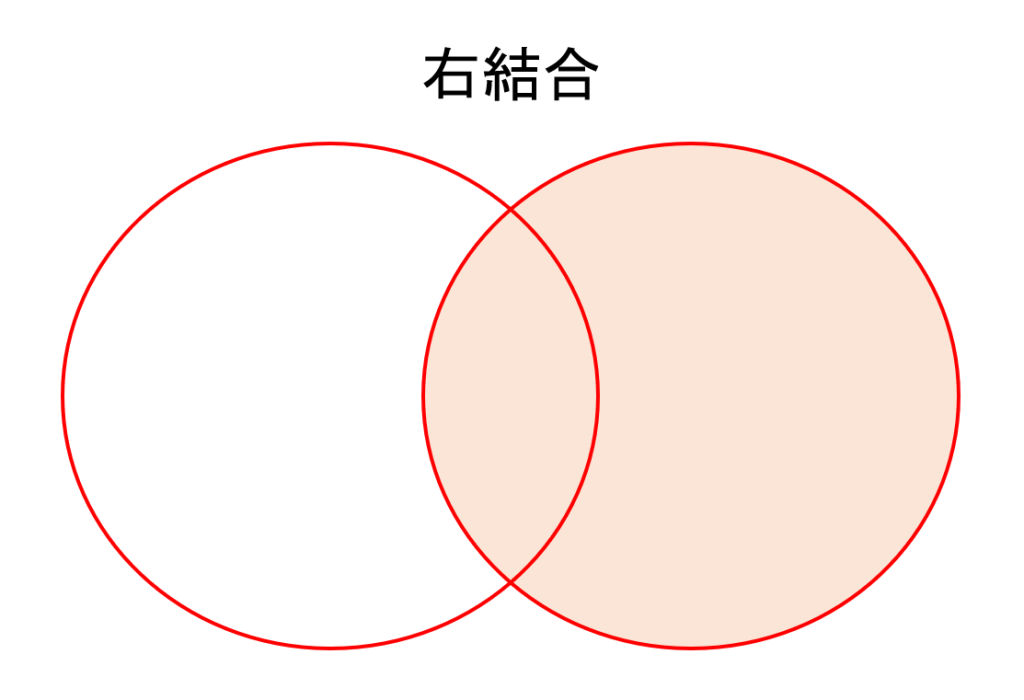
先ほどの例で右結合を行うと以下のような結果が得られます。
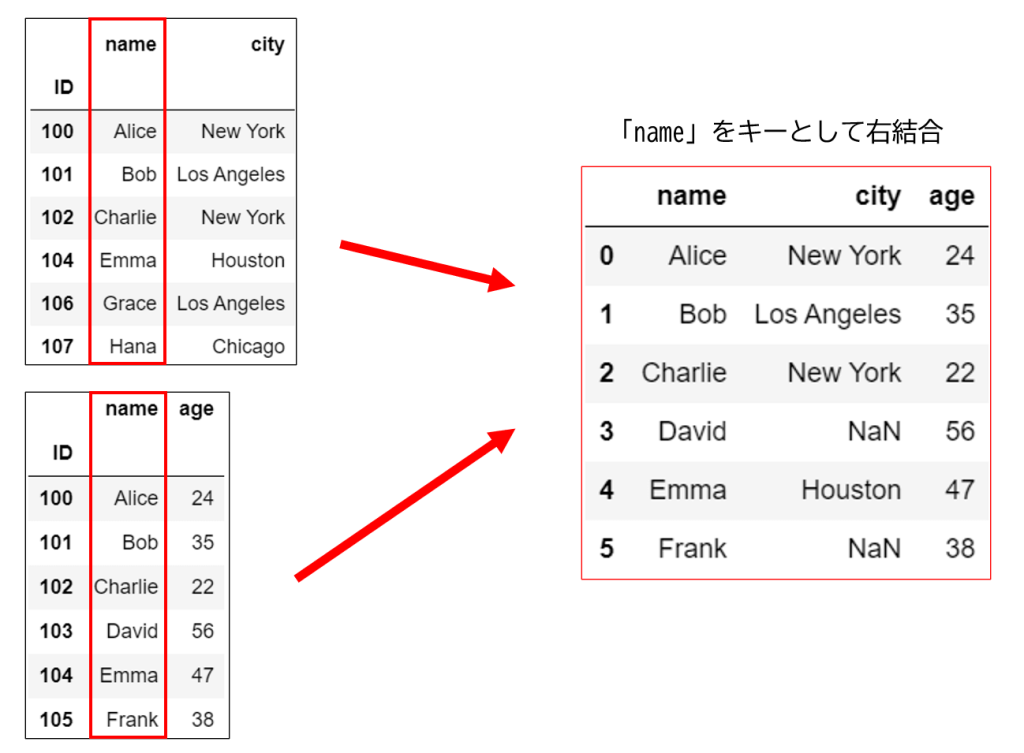
上の図において「右のデータ」は結合前の下側のデータを指します。
右のデータの「name」列にある「Alice, Bob, Charlie, David, Emma, Frank」の6つのデータが取り出されていることが分かります。
データの準備
以下のコードを実行して、今回使用する2つのDataFrame「df1」、「df2」を定義しておきましょう。
data1 = {
'ID':[100,101,102,104,106,107],
'name':['Alice', 'Bob', 'Charlie', 'Emma', 'Grace', 'Hana'],
'city':['New York', 'Los Angeles', 'New York', 'Houston', 'Los Angeles','Chicago']
}
data2 = {
'ID':[100,101,102,103,104,105],
'name':['Alice', 'Bob', 'Charlie', 'David', 'Emma','Frank'],
'age':[24,35,22,56,47,38]
}
df1 = pd.DataFrame(data1).set_index('ID')
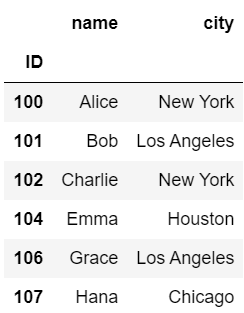
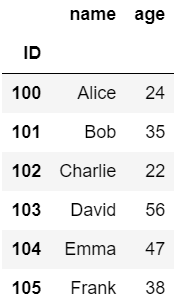
df2 = pd.DataFrame(data2).set_index('ID')作成したdf1、df2の内容はそれぞれ以下の画像の通りです。
concat()関数による縦横の連結
『pd.concat()』関数を用いると、2つのDataFrameを縦方向・横方向に連結することができます。
こちらの関数はデフォルトで外部結合が行われます。
pd.concat(結合するDataFrameのリスト)
本記事では基本的な使い方と引数『axis』『join』について解説します。
引数axis:縦結合・横結合
引数『axis』により、縦方向・横方向の連結のいずれかを選択できます。
・axis=0 → 縦方向の連結(デフォルト)
・axis=1 → 横方向の連結
まずは縦結合の例を示します。
#縦方向の連結
pd.concat([df1, df2])
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38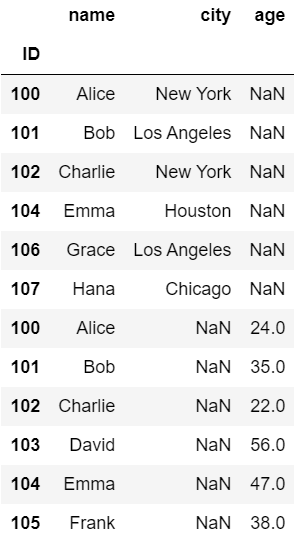
2つのDataFrameがそのまま縦に連結されているのが分かると思います。
次にaxis=1として横結合の例を示します。
#横方向の連結
pd.concat([df1, df2], axis=1)
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38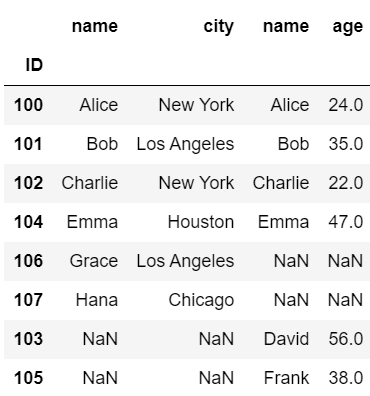
横結合においても、データが存在しない要素はNaNに置き換えられます。
引数join:内部結合・外部結合
引数『join』により、内部結合と外部結合を選択することができます。
・join=’inner’ → 2つのデータに共通する列名のみを結合
・join=’outer’ → 2つのデータに現れるすべての列名に対して結合(デフォルト)
まずは内部結合の例を見てみましょう。
#内部結合
pd.concat([df1, df2], join='inner')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38
2つのデータに共通する列は「name」なので、この列のみが縦結合されています。
続いて外部結合です。デフォルトでjoin=’outer’になっているので、join引数を指定しない場合と同様の結果が得られます。
#外部結合
pd.concat([df1, df2], join='outer')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38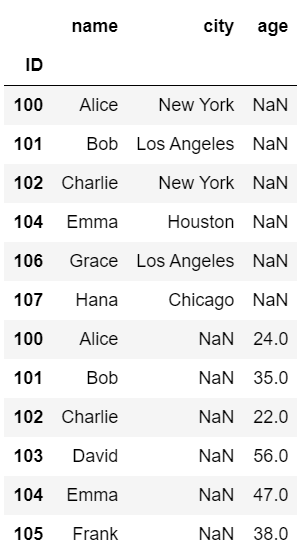
2つのデータの少なくとも一方に登場する列すべてに対して縦結合が行われます。
merge()関数による列をキーとした結合
『pd.merge()』関数を用いると、キーと結合方法を指定して2つのDataFrameを結合することができます。
こちらの関数はデフォルトで内部結合が行われます。
pd.merge(DataFrame1, DataFrame2)
のように書いたとき、第一引数の「DataFrame1」が左、第二引数の「DataFrame2」が右のデータとなります。
引数on:キーとなる列を指定
引数『on』により、キーとなる列を指定することができます。
「on=列名」とすることで指定した列名を軸に種々の結合が行われます。
省略すると自動でキーが設定されますが、プログラムを読みやすくするためにもキーを明示しておくと良いでしょう。
以下の例では、キーを「name」列としてdf1とdf2を結合しています。
#内部結合
pd.merge(df1, df2, on='name')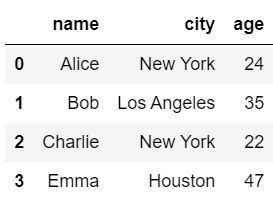
なお、デフォルトで内部結合が行われているので、両方のデータに登場する「Alice, Bob, Charlie, Emma」のデータのみが取り出されています。
引数how:結合方法を指定
引数『how』により、結合方法を指定することができます。
・how=’inner’ → 内部結合(デフォルト)
・how=’outer’ → 外部結合
・how=’left’ → 左結合
・how=’right’ → 右結合
キーを「name」列として、それぞれの結合方法の違いを確認してみましょう。
記事の冒頭で紹介した各結合方法の説明を参照しながら、結果を見比べてみてください。
#内部結合
pd.merge(df1, df2, on='name', how='inner')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38#外部結合
pd.merge(df1, df2, on='name', how='outer')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38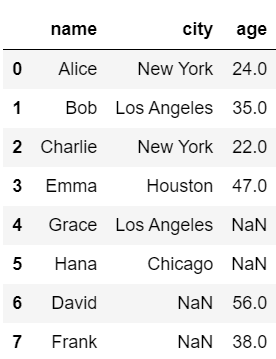
#左結合
pd.merge(df1, df2, on='name', how='left')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38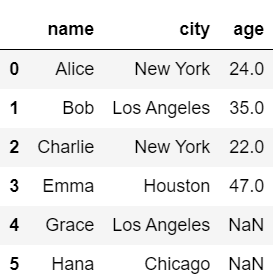
#右結合
pd.merge(df1, df2, on='name', how='right')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38
joinメソッドによるインデックスをキーとした結合
『join』メソッドを用いるとインデックスをキーとして2つのDataFrameを結合することができます。
こちらのメソッドは左結合がデフォルトになっています。
すなわち、左のデータのインデックスに合わせて結合されます。
左のDataFrame.join(右のDataFrame)
とすることで、呼び出し元DataFrameのインデックスをキーとして結合します。
なお、「pd.join()」関数は存在しないので注意しましょう。
引数how:結合方法を指定
引数『how』により、結合方法を指定することができます。
指定の仕方はmerge()関数と同様です。
・how=’inner’ → 内部結合
・how=’outer’ → 外部結合
・how=’left’ → 左結合(デフォルト)
・how=’right’ → 右結合
ここで、2つのデータに重複した列名が存在するとややこしくなるので、df2からname列を削除したdf3を使用して説明します。
#簡単のため、df2からnameを削除したdf3を用いる。
df3 = df2.drop('name', axis=1)
df3
df1とdf3を結合する例を見て、それぞれの結合方法の違いを確認してみましょう。
#インデックスによる左結合(デフォルト)
df1.join(df3)
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df3:
# age
#ID
#100 24
#101 35
#102 22
#103 56
#104 47
#105 38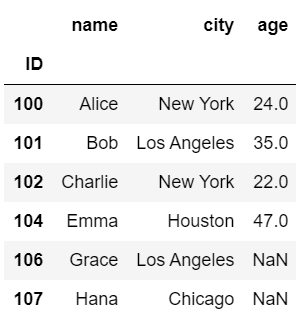
#インデックスによる右結合
df1.join(df3, how='right')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df3:
# age
#ID
#100 24
#101 35
#102 22
#103 56
#104 47
#105 38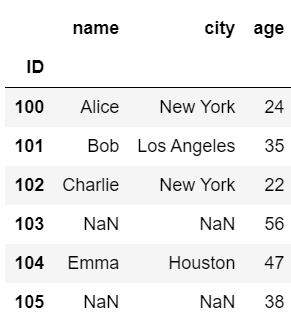
#インデックスによる内部結合
df1.join(df3, how='inner')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df3:
# age
#ID
#100 24
#101 35
#102 22
#103 56
#104 47
#105 38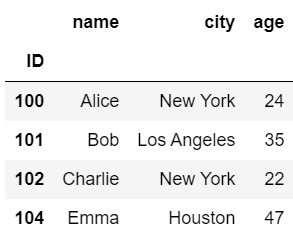
#インデックスによる外部結合
df1.join(df3, how='outer')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df3:
# age
#ID
#100 24
#101 35
#102 22
#103 56
#104 47
#105 38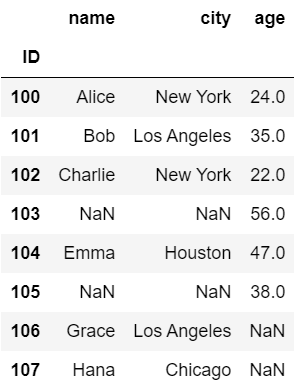
引数lsuffix/rsuffix:重複した列名に接尾語を設定
先ほど「2つのデータに重複した列名が存在するとややこしくなる」と言いましたが、重複する列名があるとエラーが出てしまいます。
この問題を回避するには引数『lsuffix/rsuffix』を用いて列名に接尾語を設定します。
以下の例では、df1とdf2で重複する列名nameについて、df2(右側)のname列に接尾語「_r」を設定しています。
#右のデータ(df2)のnameに接尾語_rを付けて重複を回避
df1.join(df2, rsuffix='_r')
#df1:
# name city
#ID
#100 Alice New York
#101 Bob Los Angeles
#102 Charlie New York
#104 Emma Houston
#106 Grace Los Angeles
#107 Hana Chicago
#df2:
# name age
#ID
#100 Alice 24
#101 Bob 35
#102 Charlie 22
#103 David 56
#104 Emma 47
#105 Frank 38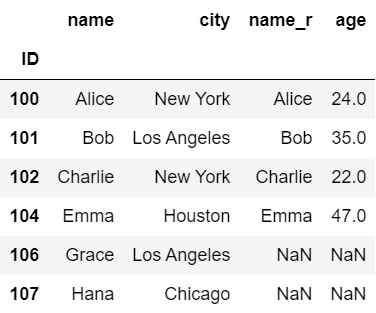

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
13章の練習問題
以下の練習問題を解いてみましょう。
練習問題
問1. 本記事中で用いたdf1,df2,df3について、(1)~(4)を出力するプログラムを書いてください。
(1) df1とdf2を縦方向に外部結合したDataFrame(concat関数を用いて)
(2) df1とdf2を横方向に内部結合したDataFrame(concat関数を用いて)
(3) 「name」列をキーとしてdf1とdf2を内部結合したDataFrame(merge関数を用いて)
(4) インデックスをキーとしてdf1とdf3を右結合したDataFrame(joinメソッドを用いて)
解答
(1)
#(1)
pd.concat([df1, df2])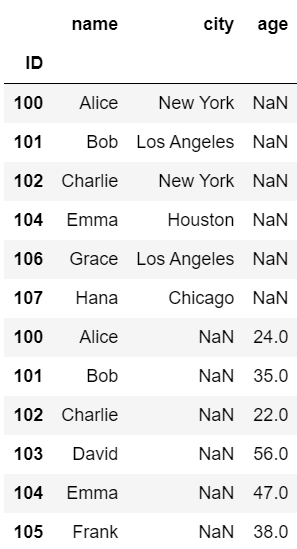
(2)
#(2)
pd.concat([df1, df2], axis=1, join='inner')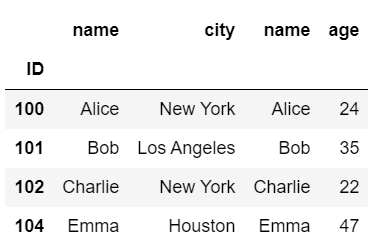
(3)
#(3)
pd.merge(df1, df2, on='name')
(4)
#(4)
df1.join(df3, how='right')
次のページへ






