

・データ分析をPythonで実装してみたい!
・実際にプログラムを実行して、何ができるのかを知りたい
そこで本記事では、サポートベクターマシン(SVM)を活用して、比較的簡単に質の良いデータ分析を実現する方法をご紹介します。難しい数式は使わず、初学者の方でもアルゴリズムをイメージで理解してみましょう。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
SVMとは?
SVM(Support Vector Machine)はサポートベクターマシンと呼ばれる機械学習アルゴリズムの1つです。SVMの仕組みは他の機械学習手法とは比較的に単純で古典的な手法ですが、現在も研究やビジネス分野で使われています。
SVMの基本的な原理として、データ空間上でクラスごとに分類する最適な境界の発見が目的です。これにはサポートベクターと呼ばれるデータポイントに対する距離を最大化する学習がなされます。
以下の図ではサポートベクターが黄色の星で示されており、赤・青・緑のラベルを分類した結果です。
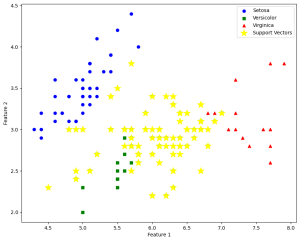
基本的にデータ分類タスクでの利用が一般的ですが、回帰や異常検出、クラスタリングなどの幅広いタスクでの応用が可能です。
例えば、SVMを回帰タスクに適用するとSVR(Support Vector Regression)と呼ばれ、予測値と実際の値の間を最小化するための境界を発見することが目的になります。
メリット・デメリット
機械学習アルゴリズムとして一般的に利用されるSVMですが、目的に対して最適かどうかを見極めることが重要です。それを理解するため、SVMのメリット・デメリットを把握してみましょう。
メリット
- 分類性能・拡張性が高い
- データの外れ値に対して影響を受けづらい
- 原理が比較的に簡単
- ライブラリで実装しやすい
一般的にSVMの分類が正確で、データの外れ値に対しても影響を受けづらい特徴があります。これはサポートベクターと呼ばれる一部のデータポイントが境界の決定に関与するためです。
距離の計算手法にはハードマージンとソフトマージンの2種類があり、外れ値の影響を小さくするソフトマージンを選択できます。
また、空間上のデータ分類を目的とする場合、3次元以上のデータ集合に対してもカーネルトリックの利用で高次元空間での分類境界の学習が可能です。そのため、非線形データに対しても十分な分類精度を提供できる汎用的なアルゴリズムだと言えます。
SVMはアルゴリズム次第で画像の分類や異常検出などのタスクに適用でき、データに対して最適に調整できることから拡張性が高い手法です。
デメリット
- 大規模なデータセットでは計算コストが膨大
- 特徴量が多くなるにつれ、計算量が増える
- ハイパーパラメータの選択が難しい
SVMは最適な分類境界を見つけるために空間上での距離を計算しますが、大規模なデータセットや高次元空間では計算コストが膨大になる場合があります。
理論的には優れている反面、計算量次第では実際のタスクに不向きな可能性に注意が必要です。特徴量の多いデータには次元削減によって特徴量の抽出や削減を前処理として組み込むことで、計算資源の問題点に対してある程度は対処できます。
また、最適な分類境界を見つけるためのコストパラメータやカーネル関数、カーネルパラメータなどを決定することが精度向上に関して重要な項目ですが、その判断が困難なデメリットもあります。
卒業研究やビジネスでの分析に!
大学の卒業研究では実験で得られた大量のデータを分析する一般的な手法です。SVMはアルゴリズムが比較的単純なため、学生にとって原理を理解しやすくなります。
ビジネスの分野でも顧客のデータを分析し、商品のレコメンデーションシステムやマーケティング効果の検証にSVMが効果的です。機械が自動的に分類すると、これまでに発見できなかった新しい属性が現れることがあり、商品の開発に活かすことができます。
scikit-learnを用いたSVMの実装
sickit-learnはPythonの代表的な機械学習ライブラリの1つで、さまざまなアルゴリズムの利用やデータ分析を簡単に実装できます。
ライブラリをインポートする際にはsklearnという名称になります。
scikit-learnのインストール
Windowsではコマンドプロンプト、Macではターミナルを開き、以下のコマンドを順番に実行してライブラリをインストールしましょう。
pip install --upgrade pippip install scikit-learnpip install numpy scipy上記コマンドでは、まずPythonのパッケージ管理ツールであるpipをアップグレードして最新の状態にします。次にscikit-learnに加え、依存パッケージであるscipyも同様にインストールします。
正しくインストールが完了したかを確認するためには以下のPythonプログラムを対話シェルなどで実行してみましょう。
import sklearn
print(sklearn.__version__)実装プログラム例
sklearnライブラリのプログラム例として、IrisデータセットをSVMで分類して、結果を描画してみましょう。
- がく片の長さ
- がく片の幅
- 花びらの長さ
- 花びらの幅
| ラベル | 日本語名 | 値 |
| setosa | ヒオウギアヤメ | 0 |
| versicolor | ブルーフラッグ | 1 |
| virginica | ヴァージニカ | 2 |
以下は、scikit-learnを利用してIrisデータセットをSVMで学習するPythonプログラムです。サポートベクターを取得し、最適な分類境界を獲得するようにマージンを最大化します。
# ライブラリのインポート import numpy as np from sklearn
import datasets from sklearn import svm # Irisデータセットをロード
iris = datasets.load_iris()
X = iris.data[:,:3]# 最初の3つの特徴量を使用
y = iris.target
# SVMモデルの訓練
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X, y)
# サポートベクターの座標を取得
support_vectors = clf.support_vectorsライブラリを利用するとSVMの訓練に必要なプログラムは2行のみです。
データの分析結果を可視化する
SVMでの学習後、サポートベクターが正確に分類できているかを知るために、matplotlibライブラリを使って3次元空間上で表示してみましょう。インストールには
pip install numpy matplotlibをコマンドプロンプトやターミナル上で実行します。
以下は、データの可視化プログラムと実行結果です。赤・緑・青色で表示される点は花のデータポイントです。IrisデータをSVMで学習して得られたサポートベクトルは薄い青色の丸で囲って表示します。
# ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import datasets
from sklearn import svm
# Irisデータセットをロード
iris = datasets.load_iris()
X = iris.data
y = iris.target
# SVMモデルの訓練
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X, y)
# サポートベクターの座標を取得
support_vectors = clf.support_vectors_
# 3Dプロット
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# データポイントのプロット
ax.scatter(X[y == 0, 0], X[y == 0, 1], X[y == 0, 2], c='b', marker='o', label='Setosa')
ax.scatter(X[y == 1, 0], X[y == 1, 1], X[y == 1, 2], c='g', marker='s', label='Versicolor')
ax.scatter(X[y == 2, 0], X[y == 2, 1], X[y == 2, 2], c='r', marker='^', label='Virginica')
# サポートベクターのプロット
ax.scatter(support_vectors[:, 0], support_vectors[:, 1], support_vectors[:, 2], c='lightblue', marker='o', s=200, label='Support Vectors', edgecolors='k')
# 軸のラベル付け
ax.set_xlabel('Feature 1')
ax.set_ylabel('Feature 2')
ax.set_zlabel('Feature 3')
plt.legend()
plt.show()
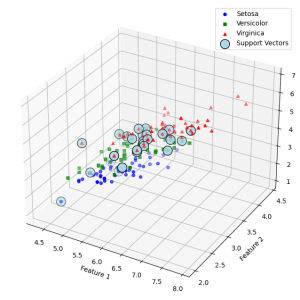
3次元空間上でも花の種類がサポートベクターによって分類されたことが読み取れます。さらに複雑な高次元データに対しても、SVMはパラメータ設定次第では分類が可能です。
SVMの応用と可能性
SVMの応用例としていくつか見てみましょう。
- スパムメールの検出
- 感情分析
- DNA配列の分類
- タンパク質の機能予測
- 株価の予測
- 疾患の診断
- 異常検出
- 物体検出
など、拡張性の高さから幅広い分野で活躍する技術です。
例えば、非線形データを線形に分離可能な形に変換する数学的な手法を用いたカーネルトリックでは、非線形な分類タスクに対しても適応が可能です。カーネルトリックはカーネル関数を用いて、非線形データを高次元の特徴空間に写像する手法であると解釈できます。
SVMの注意点
- 研究分野では特に原理を理解する必要がある
- 必ずしも最適な手法だとは限らない
- ハイパーパラメータの設定について知る
SVMは一般的に用いられるアルゴリズムですが、必ずしも最適な手法だとは限りません。他の機械学習アルゴリズムの方が高い精度を発揮する可能性があるため、データの特徴や目的に合わせることが大切です。
また、研究の分野では特に重要視されますが、SVMの原理を理解せずに分析を行うことは好ましくありません。アルゴリズムを数学的に理解し、どのような処理が行われるのかを理解することで、ハイパーパラメータの設定やSVMを利用するかを判断できます。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
SVMは比較的単純なアルゴリズムですが、高い精度で幅広いデータの分析ができるツールです。Pythonではsklearnライブラリを利用すると簡潔に実装ができました。さまざまな場面での応用例がありますが、原理を理解することは大切なので、積極的に勉強を進めてみましょう。





