Pythonを学び始めた方のなかには、「sklearnとは何なのか?」と気になっている方も多いのではないでしょうか?
今回は、sklearnの概要やできることをわかりやすく解説します。また、重回帰分析のサンプルコードを通じて、sklearnの正しい実装方法も理解できます。
sklearnを使いこなせるようになりたい方や機械学習を自力で実行できるようになりたい方は、ぜひ最後までご覧ください。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
Pythonの「sklearn」とは?scikit-learnとの違い
sklearnとは「scikit-learn」をプログラムコード上で呼び出すときの名前です。
scikit-learn(sklearn)は、Pythonの機械学習向けライブラリで、回帰・分類・クラスタリングのアルゴリズムと各種データが収録されています。
sklearnもscikit-learnを指す言葉であるため、エラーを検索するときや本を探すときにも使って問題ありません。
ただし、プログラミングコード上でscikit-learnと記述すると、呼び出せずエラーが発生します。
そのためscikit-learnを使用したい場合には、下記のように記述する必要があります。
from sklearn

Pythonのsklearnでできること
sklearnでは、機械学習を実装するためのクラスやメソッドが充実しています。そのためsklearnを使いこなせるようになれば、下記のように機械学習で必要なあらゆることができるようになります。
- データの準備
- 実装済みアルゴリズムによるモデル構築
- メソッドを使った学習・テスト・評価
Pythonで機械学習をマスターするためにも、これからsklearnでできることを1つずつチェックしてみましょう!
データの準備
sklearnは機械学習向けのライブラリであるため、機械学習で使えるデータが多数収録されています。下記が2023年時点で提供されている全13種類のデータの一部です。
| トイデータ | 実世界データ |
|---|---|
| ・アヤメの品種データ
・ワインの品種データ ・手書き数字データ |
・カリフォルニアの住宅価格データ
・ニュース記事データ ・森林のデータ ・有名人の顔写真データ |
トイデータは機械学習用に前処理が行われており、特別な加工をすることなく機械学習モデルの学習やテスト時に使えるように整えられています。一方で実世界データは、普段見るデータに近いものが多く、欠損値や異常値などがそのまま含まれているのが特徴です。
そのため、機械学習モデルを試したいだけならトイデータを使い、データの前処理から勉強したい場合には実世界データを使うなどと、自分の目的に合わせて使い分けができます。TensorflowなどAI開発向けのライブラリと比べて、sklearnは実用的なデータが豊富なため、幅広い機械学習タスクで活用可能です。
実装済みアルゴリズムによるモデル構築
sklearnでは、機械学習の古典的なアルゴリズムがクラス化されています。下記がsklearnで使用できる機械学習アルゴリズムの一例です。
| 教師あり学習 | 教師なし学習 |
|---|---|
| ・決定木
・ナイーブベイズ ・サポートベクター回帰 ・ニューラルネットワーク |
・k-means
・混合ガウスモデル ・主成分分析 |
sklearnを使わない場合には、自分で1から数式を実装する必要があります。一方でsklearnを使えば、機械学習の深い知識がなくても機械学習モデルを構築可能です。そのため適用したいモデルがある場合には、スムーズに試せるメリットがあります。
メソッドを使った学習・テスト・評価
sklearnでは、機械学習の各工程で使えるメソッドが用意されています。例えば、下記のように学習とテスト、評価で使えるメソッドがあります。
| 学習用メソッド | テスト用メソッド | 評価用メソッド |
|---|---|---|
| fit | predict | ・r2_score(決定係数)
・mean_squared_error(平均二乗誤差) ・accuracy_score(正解率) ・f1_score(F値) |
sklearnを使えば、学習・テスト・評価それぞれに必要な膨大な計算用のプログラミングも不要です。
【コード付き】Pythonのsklearnで重回帰分析を実行する方法
では、sklearnを使って重回帰分析を行ってみましょう!
今回の重回帰分析のテーマは、「住宅のスペックや地区の情報から住宅価格を予想する」ものです。
「世帯収入の中央値」や「築年数の平均」など8つの説明変数から、住宅価格を予測します。
sklearnで重回帰分析を実行する方法を下記の順番で紹介します。
- 必要なライブラリのインストール〜インポート
- データの選択~前処理
- 学習用とテスト用データに分ける
- 回帰モデルの決定
- 回帰モデルの学習とテスト
- 評価
実行環境は下記のとおりです。
Windows
Spyder 5.2.2
sklearn 1.3.1
各コードを見ながら一緒に手を動かしてみましょう!
余力がある方は、sklearnを使った「主成分分析」の実装方法も下記でチェックしてみてくださいね。

必要なライブラリのインストール〜インポート
まずは、実行に必要なライブラリ・フレームワークをインストールする必要があります。
今回使用するsklearn・Numpy・Pandasは、Anacondaではデフォルトでインストール済みなので不要です。過去にアンインストールしてしまった場合には、下記をAnaconda Prompt上で打ち込み、再インストールを行ってください。
conda install scikit-learnまた、バージョンが古い場合にはエラーが発生する原因にもなることがあるため、下記のようにアップデートを行いましょう。
conda update scikit-learn次は、AnacondaのSpyder上でエディタを立ち上げて各種ライブラリやデータをインポートします。慣れた環境がある場合には、Spyder以外でも問題ありません。
また今回は実世界データのうち、「カリフォルニアの住宅価格データ」を使用します。インポートのコードは、下記のとおりです。「# コメント」は、それぞれの下側にあるコードの内容を説明しています。
import numpy as np
import pandas as pd
# カリフォルニアの住宅価格データ
from sklearn.datasets import fetch_california_housing
# データ分割
from sklearn.model_selection import train_test_split
# 重回帰分析
from sklearn.linear_model import LinearRegression
# 評価指標:決定係数
from sklearn.metrics import r2_scoreなお、機械学習に必要なフレームワークは、下記を参考にしてくださいね!

データの選択~前処理
次に、学習とテストに使えるようにデータを準備する必要があります。
sklearnのデータでは、「データのクラス.data」とすると説明変数のみが返り値として渡されて、「データのクラス.target」とすると目的変数のみ渡されます。
では、機械学習ができるように、下記コードを参考にしてfetch_california_housingクラスの格納データを説明変数と目的変数に分けてください。
ca_data = fetch_california_housing()
# 説明変数
x = ca_data.data
# 目的変数
y = ca_data.target次に、説明変数と目的変数にどのような値が含まれているかPandasのデータフレームを利用して見てみましょう。
データフレームとは、Excelのような見た目で、データ分布の可視化や最大値などの計算処理ができる配列です。
# データフレームへ格納
df_x = pd.DataFrame(x, columns=ca_data.feature_names)
df_y = pd.DataFrame(y, columns=["price"])
# 説明変数と目的変数の内容を表示
display(df_x.head())
display(df_y.head())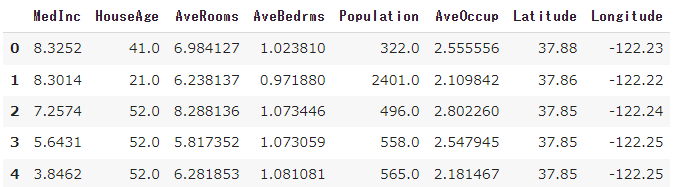
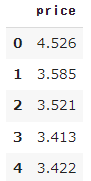
出力した内容より、カリフォルニアの住宅データの説明変数と目的変数には、下記のデータが含まれていることがわかりました。
| 説明変数のデータ | 目的変数のデータ |
|---|---|
| ・世帯収入の中央値(MedInc)
・築年数の平均(HouceAge) ・部屋数の平均(AveRooms) ・寝室数の平均(AveBedrms) ・各地区の人口(Population) ・世帯人数の平均(AveOccup) ・各地区の緯度(Latitude) ・各地区の経度(Longitude) |
住宅価格 |
Pandasを使えばデータの内容を簡単に可視化できるため、操作に慣れていない方は下記をチェックしてみてくださいね!

カリフォルニアの住宅価格データには欠損値や極端な異常値が含まれていないため前処理は不要ですが、実世界データの多くでは前処理が必要になります。データの前処理については、下記で詳しく解説しています。

学習用とテスト用データに分ける
使うデータが決まれば、学習用とテスト用データに分ける必要があります。sklearnでは、メソッドの「train_test_split」と呼ばれる学習とテストデータに分割できます。
では、train_test_splitの引数を設定し、学習とテストデータへ分割したコードを見てみましょう。
# test_size:テストデータの割合
# random_state:乱数シード値
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)「test_size」は、全データ数のうちテストデータが占める割合を指定する引数です。学習データ数:テストデータ数=9:1もしくは、8:2や7:3が一般的です。
「random_state」は、データ分割の再現性を保つための引数です。値を指定しておくことで、コンパイルしなおしても同じ内容の学習とテストデータへ振り分けられます。
random_stateを指定しないと、ほかを同じ条件にしても試行する度に若干結果が変わってしまうため、適当な数値を与えて固定するようにしましょう。
また、train_test_splitの返り値は、「説明変数の学習データ・説明変数のテストデータ・目的変数の学習データ・目的変数のテストデータ」です。それぞれ対応するように、適切な格納先を記述しましょう。
回帰モデルの決定
次に、sklearnで収録されている機械学習モデルのなかから適切なモデルを選択しましょう。今回は、sklearnの重回帰モデルを使います。sklearnでは、下記のように1行でモデルを定義できます。
# 重回帰モデル
rl_model = LinearRegression()興味がある方は、下記の記事を通じてExcelで重回帰分析を行う場合と比較してみてくださいね。sklearnの簡単さが実感できますよ!

回帰モデルの学習とテスト
データとモデルの準備が整ったので、学習とテストを行いましょう!下記がそれぞれのコードです。
# 学習
rl_model.fit(x_train,y_train)
# テスト
y_pred_test = rl_model.predict(x_test)学習メソッドのfitの引数に説明変数・目的変数の学習データを与えることで、自動的に重回帰分析の計算を実行してくれます。
predictでは、説明変数のテストデータを与えることで、学習済みモデルで予測した値が返り値として渡されます。なおpredictには、答えとなる目的関数をpredictの引数に入れないように注意してくださいね。
評価
最後に、どれくらいのモデルが上手く予測できたかどうかを定量評価しましょう。
複数の定量評価指標がありますが、今回は「決定係数」で評価を行います。決定係数のコードと結果を出力するコードは、下記のとおりです。
# 決定係数
r2_test = r2_score(y_test, y_pred_test)
# テスト結果の表示
print("R2スコア(テストデータ):", r2_test)sklearnのmetricsモジュールの「r2_score」は、第一引数に目的変数の真値データを与えて、第二引数に予測データを与えると決定係数を出力します。metricsモジュールには、決定係数以外にもF1スコアや平均二乗誤差など、さまざまな評価指標が収録されているので、チェックしてみてくださいね。
シンプルに重回帰モデルを実行した決定係数の結果は、「約0.57」となりました!決定係数は0から1の範囲の値をとり、1に近づくほど予測モデルの精度が高いことを示します。予測結果は、選択したモデルや各種ハイパーパラメータの値によって大きく変わるため、より精度を上げたい場合には試行錯誤してみましょう!
なお評価指標を選ぶ際には、下記を参考にしてくださいね。

sklearnの上手な使い方
sklearnを上手に使うためには、下記の2つを使いこなせるようになることが大事です。
- チートシート
- チュートリアル
チートシートとは自分が持つデータの条件から「はい・いいえ」を選択することで、適切なモデルを提示してくれるものです。
そのためチートシートを使えば、知見がなくても膨大な機械学習モデルのなかから正しいモデルを選べるようになるメリットがあります。
また、sklearnの公式サイトでは各機械学習モデルごとにチュートリアルが公開されています。
そのためチュートリアルを参考にすれば、モデルの基本的な使い方を習得できるのです。
チートシートとチュートリアルを活用して、sklearnのスキルを高めましょう!

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
sklearnは、scikit-learnをプログラミングコード上で呼び出すときの名前です。
sklearnでは、データの準備から機械学習モデルの学習、評価まで機械学習に必要なメソッドやクラスがサポートされています。そのためsklearnを使いこなせるようになれば、基本的なモデルを使った機械学習ができるようになるため、学んで損はありません。
sklearnを上手に活用するうえでは、公式のチュートリアルやチートシートを使って独学する選択肢もありますが、効率を重視するのであればスクールがおすすめです。
なかでも「Tech Teacher」では、豊富なAIの経験を持った講師から直接指導してもらえるため、正しいsklearnの使い方を迅速に習得できます!お気軽に「資料請求・無料体験」にお申込みください。