AIの勉強をしてみたい!と思いつつも、
- AIを自分でプログラムして作成するのはハードルが高そう
- プログラムが難しくてAIの勉強は向いていないんじゃないかな?
と思っている人は多いのではないでしょうか。特に、AIの勉強でどのようなことをするかがわからないと、これから時間をかけてAIの勉強をしていいのかどうか、という判断もできません。
今回は非常に簡単な画像の認識プログラムを作成することでAIの基礎を勉強していきます。一通り動かしてみることで、「このようなことをやっているのか」ということを理解していただき、「このような勉強をすればいいのか」ということを体感してください。
- 簡単な画像認識AIを作成できます
- AIの作成を通してAI作成の難易度がわかります
- AIの作成に必要な知識がわかります

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
AIとは
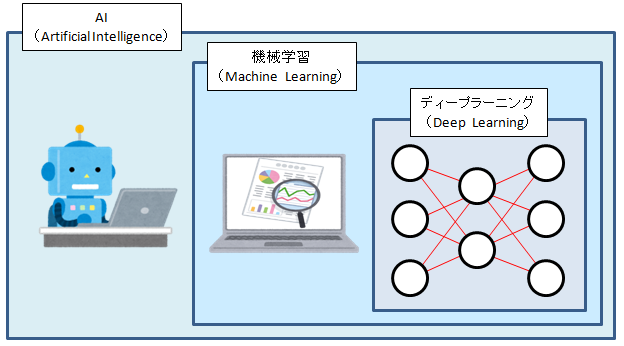
AIとは「Artificial Intelligence」の略で、直訳すると「人工知能」となります。
この人工知能の定義はあいまいで専門家の中でも定義がいくつか存在していますが、ディープラーニングで有名な東京大学の松尾先生は「人工的に作られた人間のような知能、ないしはそれをつくる技術」と定義されています。
そのAIはChat-GPTなどの文章認識、DALLE2などの画像生成、YOLOなどの画像認識、DeepLなどの機械翻訳など、様々な場面で活用されています。
AIは定義からすると上図のようになり、AIの中に機械学習やディープラーニングが含まれるのですが、「AI」と言うと、この「ディープラーニング」の部分を思い浮かべる人も多いのではないでしょうか。
今回はこのディープラーニングの内容を使って、簡単な画像認識AIを作っていきます。AIやディープラーニングというと難しそうに感じますが、基本はそれほど難しくありません。
もちろん難しい認識や高精度な認識など、突き詰めていくと非常に難しいものもありますが、まずは実際に動かすまではそんなに難しくないことを体感していただき、できることを実感しながら勉強を進めていけたらいいのではないでしょうか。

AIの作り方
学習内容のロードマップ
AI、特に機械学習に関してのロードマップは以下のページで解説していますので、こちらを参考にしてください。

Pythonの勉強
後程説明するプログラムを見ていただくとわかるように、コードは「Python」を使用して書いています。まず、Pythonに関して最低限の知識と実行できる環境が必要です。以下参考にして準備してください。

簡単な画像認識AIを作ってみる
解説は後にして、まずはどの程度のものを書けば最低限のAIを作れるか見ていただきましょう。
これから紹介するのは「mnist」と呼ばれる手書きで書かれた数字を認識して、正しく判断するプログラムです。まずはプログラム全体を記載します。この後に部分ごとの解説をします。
import keras
from keras.layers import Flatten, Dense
import matplotlib.pyplot as plt
mnist = keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
model = keras.Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model.fit(train_x, train_y, epochs=5)
model.evaluate(test_x, test_y)
実際に実行してみると、途中の計算結果の後で上のような二つの数字が出てきました。この右側の数値、約0.94が今回のプログラムでの正解率です。これだけ書いただけで94%も正解できるうえに、さらに作りこめばもっと良い数値が出ます。
ここからどんなことをしているか解説していきます。
ライブラリのインポート
ここで行うこと
- ライブラリをインポートしてライブラリを使用する準備をする
import keras
from keras.layers import Flatten, Dense
import matplotlib.pyplot as plt使用するライブラリをインポートします。簡単に説明すると、今回使用する機能を使えるように読み込みます。
今回はディープラーニングを使用できるように「keras」と、画像を表示させるために「matplotlib」を読み込んでいます。インポートに関しては下の記事にまとまっていますので参考にしてください。

データを読み込む
ここで行うこと
- 使用するデータを「mnist」から読み込む
- 読み込んだデータがどんなものかを確認する
mnist = keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()手書きのデータを練習用で誰でも使用できるように、「mnist」というデータとその正解ラベルをまとめた「データセット」が公開されています。上記のようにすることでトレーニング用データ、テスト用データを読み込むことが可能です。
ここで読み込んだデータを見てみましょう。さきほど「train_x」という名前で読み込んだので、その1番目のデータを見るには以下のように入力します。データは0から順番に番号が割り振られているので、一番最初のデータを見るときには「0」を指定します。
train_x[0]
数字の羅列が出てきましたね。これだけでは少しわかりにくいので、以下のように入力してみてください。
plt.imshow(train_x[3])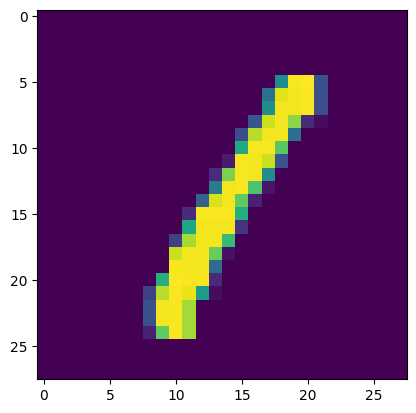
これは4番目のデータを画像表示させたところです。先ほどと同じように、0から始まっているので「train_x[3]」が4番目を示してます。画像表示すると手書きの「1」を表していることがわかります。読み込んだデータはこの文字を0から255の数字で表したものになります。
先ほどの「3」の部分を変えていくつか入力してみると、読み込んだ手書き文字をいくつか確認することができます。

ディープラーニングモデルを作成する
ここで行うこと
- 「keras」の「Sequential」を使用してAIモデルを作成する
- 作成したモデルを確認する
model = keras.Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])ここでは先ほど読み込んだデータを認識するためのモデルを作成します。これは最も簡単な作成方法で、モデルを作成したところです。
kerasのSequentialにモデルを渡してやることで、簡単にモデルを作成することができます。今回作成したモデルは、
- Flatten:データを一列に並べる
- Dense:全結合層を追加する
という処理をしています。どのようなものが出来上がっているかは以下のように確認します。
model.summary()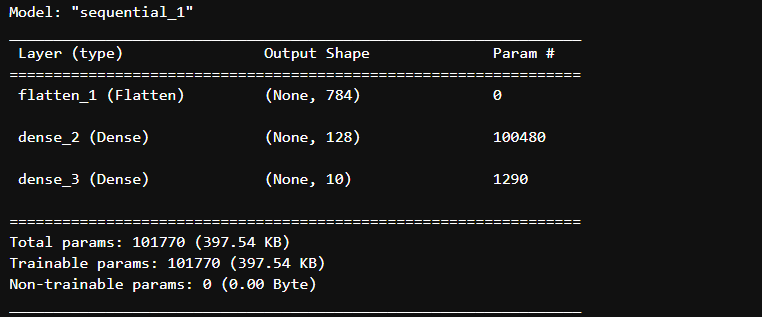
入力部分は28×28のデータを一列に並べた784の要素がある層、その次に128の要素がある層、最後に10の要素がある層で構成されています。784のデータを入力して、最終的に10の層で出力するわけですね。
出力は手書き文字が1~0の10個に分類されるため、784の入力された数値から最後の10の要素のどの出力の可能性が高いか、を予想して結果を出力します。
モデルをcompileする
ここで行うこと
- モデルを「compile」して学習のプロセスを決定する
model.compile(
optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)ここではモデルの学習プロセスの設定をします。
- optimizer:パラメーターを更新する方法。
- loss:正解と予測の誤差。これを最小にするように学習が進んでいく。
- metrics:モデルの性能評価に用いる関数を設定します。’accuracy’は正解率を示します。
ここまで行うとモデルの設定が完了します。
モデルの学習
ここで行うこと
- いままで作成してきたモデルを学習させる
model.fit(train_x, train_y, epochs=5)先ほどまでで作成したモデルに、実際にデータを流し込んで手書き数字の画像とラベルの関係を学習します。一つ目の引数に学習するデータ、二つ目にその正解ラベル、epochsに学習する回数を設定します。
ここまで行うことで、「model」が手書き文字を認識できるモデルになります。
学習結果の確認と結果の予測
ここで行うこと
- 「evaluate」を用いてデータの予測と実績を比較する
- 「predict」を用いてデータそれぞれの予測を確認する
model.evaluate(test_x, test_y)evaluateを用いることで予測結果の正解率を確認することができます。一つ目の引数に予測をするデータを、二つ目の引数に正解を入力します。先ほども確認しましたが、二つ目の数値、が正解率で約94%の正解率となっています。
model.predict(test_x)[0]
では、一つ一つ個別のデータを確認してみましょう。predictにデータを入れることで予測結果を得ることができます。predict()の後ろに[0]をつけて1番目の予測結果を見てみましょう。
上記のように10個の数字が返ってきました。これは、順に0,1,2,3・・・である可能性を示しています。今回は「7」の確立が99%と言っているので、「7」が正解と思われます。
plt.imshow(test_x[0])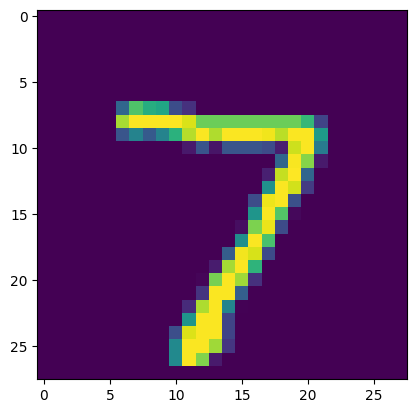
では、入力された手書き文字を見てみましょう。「7」のようですね。念のため、答えのラベルも確認します。
test_y[0]
やはり「7」が正解でしたね。
もう少し画像認識AIに触れてみる
今回は初学者を対象として、まずは「動かせる」ことを目的に解説しました。今回の内容と同様、初学者にわかりやすい画像認識問題を以下のページで取り扱っているので、この後ぜひ挑戦してみてください。


『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回は簡単な画像認識AIを作成してみましたが、いかかでしたか?非常に初歩的なモデルでしたが、そんなに難しくなく作成することができたのではないでしょうか。
今回習得した画像認識の知識をもとに、さらにレベルアップアップしていただければと思います。