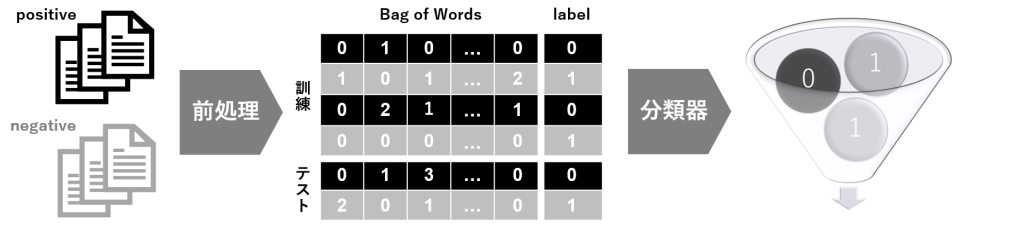
Bag of Words(BoW)は、単語の出現頻度を基に文章を数値ベクトル化する自然言語処理の技術です。言語をコンピューターで扱う自然言語処理において、文字列を数値化することは最初の重要なステップになります。
本記事ではまず、機械学習の1分野である自然言語処理について紹介します。そして、BoWやその他の文字列を数値化する技術を取り上げ、BoWの応用方法ついて解説します。
・Natural Language Processing (NLP)
・Bag of Words (BoW)
・Document Classification

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
Natural Language Processing (NLP)
自然言語処理(Natural Language Processing: NLP)は、人間が日常使用する自然言語(英語や日本語、スペイン語など)をコンピューターに理解させ、処理できるようにするための技術分野です。NLPは、文章データを解析して言語の構造や意味を抽出するために広く利用されています。
具体的な応用タスクとしては、文章分類や文章生成、情報検索、文章クラスタリングなど多岐にわたり、さまざまなタスクに自然言語処理が応用されています。
例えば、文書分類にはスパムメールの検出や感情分析などが含まれます。また、文章生成タスクには機械翻訳や質疑応用、要約タスクなどがあります。
Googleの機械翻訳は、ニューラルネットワークを用いて翻訳精度を向上し、OpenAIのChatGPTは、質問に対して人が書いたような自然な文章を返すようになり、自然言語処理は近年、特に注目されています。
以下の記事では自然言語処理の概要と仕組み、利用例を紹介しており、合わせて読むことでより本記事の内容を理解できると思います。

機械学習で扱うデータには、数値や記号などの表でまとめられる構造化データと文章などの非構造化データに分けられます。数値データの場合、何かしらの機械学習モデルにそのまま入力し、出力の傾向や入力の関係性の学習が可能です。
しかし、自然言語処理で扱う非構造化データの場合、そのままでは扱えず、何かしらの数値に変換する処理が必要となります。文章データを構造化データに変換する処理がBoWになります。
Bag of Words (BoW)
文章のベクトル化
Bag of Words(BoW)は、文章内の単語の頻度を用いて文章を数値ベクトルに変換する方法です。
ある文章内で「犬」や「猫」の単語が高頻度であれば、ペットに関する内容と推察できたり、「野球」や「サッカー」の単語が高頻度であれば、スポーツに関する内容と推察できたりします。同様に、BoWでベクトル化した文章は、単語頻度を基に文書分類タスクなどに応用が可能です。
具体的な手順としては、文章データを単語などの単位に分割し、出現頻度をカウントしてベクトルとして各文書を表現します。各文書が数値の表形式として構造化データとなり、文章データ機械学習アルゴリズムを適用できるようになります。

BoWは全ての単語を同等に扱って文書を分析できる形に変換しますが、各単語に重要度を付与してベクトル化する方法にTF-IDF(Term Frequency-Inverse Document Frequency)があります。
この方法では、BoWに相当する文書中の単語の出現頻度を表す指標「TF」と単語の出現する文書の割合を逆数で表した指標「IDF」を掛け合わせた値を使用します。
そのため、BoWと同様に出現回数の多い単語のTF値は大きくなりますが、他の文章でも出現が高いとIDFが小さくなるため、文書内での単語の重要性を反映して文章をベクトル化できます。
例えば、「その」や「この」などの指示語、「です」や「ます」の文末敬体、「、」や「。」の句読点などは、一般的に文章中での頻度が高くなりますが、文章の内容とはあまり関係なく、IDFで調整できるようになるのです。
BoWやTF-IDFは文脈情報を無視し、単語の順序に関係なく処理するため、文の意味を正確に捉えるのは難しい場合があります。単語(Words)を順序に関係なく袋(Bag)に詰める様子からBag of Wordsと呼ばれます。
TF-IDFについては、以下の記事で詳しく解説しています!

単語のベクトル化
BoWは単語の出現頻度に基づいて文章をベクトル化しましたが、同じように単語をベクトル化する技術もあります。各単語をベクトル化して系列として扱うことで、より詳細に文章の意味を捉えることが期待できます。
単語をベクトル化する技術にはカウントベースの手法と推論ベースの手法があります。
これはどちらも、文章中の単語の意味は周囲の単語によって形成されるという「分布仮説(Distributional hypothesis)」に基づく方法が用いられています。
カウントベースの手法では、文章中の対象単語の周囲に出現する単語数をカウントして共起行列を作成します。各単語ごとに共起する単語数を示した表形式のデータとなります。
BoWでのTF-IDFによる改良と同じく、単に出現頻度の高く、周囲にきても重要でない単語の寄与を下げるために、共起回数を単語の出現確率で補整して共起行列を作成します。
出現確率で補正した行列を相互情報量(Pointwise Mutual Information: PMI)と呼びます。共起行列は、辞書に含まれる次元数のサイズとなりますが、これを特異値分解により、次元削減できます。
推論ベースの単語をベクトル化する手法には、Word2Vecがあります。Word2Vecは、上記のカウントベースの手法とは異なり、周囲の単語から目的の位置にどのような単語がくるかを予測する問題に分布仮説を帰着させます。そして、2層のニューラルネットワークを用いて単語をベクトルに変換します。
Word2Vecで得た単語ベクトルは、中間層の次元数に圧縮され、単語の意味や文法を反映し、類似性や加法性といった特徴を持ちます。同じようなアルゴリズムで、文章をベクトル化するDoc2Vecと呼ばれる手法もあります。
以下の記事ではWord2Vecの概要と仕組み、利用例を紹介しております。

Document Classification
BoWをレビュー分析などの文書分類タスクに応用する方法を紹介します。
文書分類タスクでは、ポジティブかネガティブかラベル付けしたテキストデータセットが必要になります。目的のタスクに合ったラベル付けデータがない場合は、事前に人の手でラベル付けするアノテーションと呼ばれる作業が必要になります。
データセットが準備できれば、テキストに対して不要な文字列の削除など前処理を施し、BoWで文書をベクトル化します。文書の長さや文書数が多いと単語数も膨大となる場合は、頻度の高い上位3000個などに上限を設けます。これにより各文書を同じ次元数のベクトルとして扱うことができます。TF-IDFの場合でも同じように利用可能です。
ラベルに関しては、2値分類の場合、ポジティブとネガティブをそれぞれ0と1のダミーの数値に変換します。これにより文書とラベルを表形式にまとめることができます。
文書ベクトルと数値ラベルをまとめた表形式のデータに対して、通常の機械学習で利用する決定木などの分類器を用いて学習させることができます。
一般的には、データを全て学習に利用せずに訓練データとテストデータに分割し、学習データで訓練した分類器に対して、テストデータで汎化性能を評価します。分類性能の評価は、分類器で予測したポジティブとネガティブに対して、実際のポジティブとネガティブを表形式で表した混同行列を用いることで正確な評価が可能になります。
文書分類だけでなく、その他のタスクにおいても同様にBoWを利用でき、最後の機械学習モデルを変更することでそれぞれ適したタスクに転用できます。
以下の記事では決定木の実装方法や混同行列による評価方法を紹介しており、合わせて読むことでより本記事の内容を理解できると思います。


『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
データサイエンスを学習するならTech Teacherで!
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。