

クロスバリデーションについて、予測値の精度アップに非常に役に立つことは有名ですが、
どうやってつかうの?
どんな時に使うの?
結果はどう確認するの?
という疑問をお持ちの方も多いと思います。今回はこのあたりを中心に、クロスバリデーションについて解説していきましょう。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
クロスバリデーションとは?
クロスバリデーションは日本語で「交差検証」といいます。

通常機械学習を行う際、上図のようにデータを訓練データと検証データに分けてモデルをトレーニングし、そのモデルを使用して結果を予測すると思います。
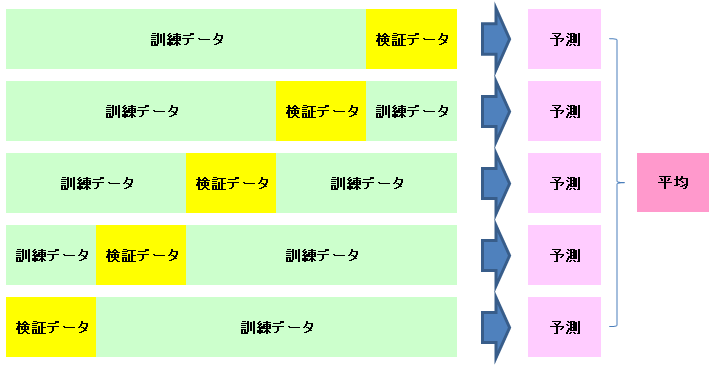
クロスバリデーションでは、この訓練データと検証データを上図のように入れ替えて、それぞれのモデルで予測した値の平均値、もしくは最頻値を最終的な予測値として使用します。
クロスバリデーションを行うことにより、一般的には汎化性能、予測精度ともに向上する傾向にあります。これは、検証データを変えることにより特定のデータにオーバーフィッティング(過学習)することを防ぐためです。
クロスバリデーションの実施方法
KFoldを使用する
クロスバリデーションの意味は分かったと思うので、実際にどのように実施するのかを考えてみます。上の図を見ると、データを5分割にしているので、実際にデータを5つに分けて5回解析を行えばよさそうです。
しかし、実際にデータを5分割して、5回解析して・・・とやっていくのはめんどくさそうです。それを解決するものとして、「KFold」が存在します。これを使用してクロスバリデーションをしてみましょう。
事前準備
今回はscikit-learnの木の分類データセットを使用してみましょう。以下のようなデータを準備しました。
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_covtypeまずは必要なライブラリをインポートしておきます。
data = fetch_covtype()
df = pd.DataFrame(data.data, columns=data.feature_names)
df_t = pd.DataFrame(data.target, columns=['target'])
df = pd.concat([df, df_t], axis=1)
df.head()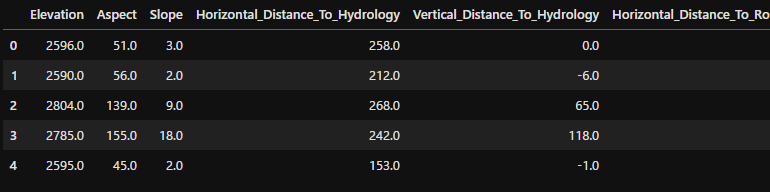
df.shape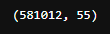
55カラムのデータが581,012データ準備できました。
df_train = df.iloc[:54000, ]
df_test = df.iloc[54000:, ]まずは先頭の54,000データをトレーニング用、それ以降をテスト用データに切り分けておきます。
KFloldの動作
from sklearn.model_selection import KFold
kf = KFold(n_splits=5)
for _train, _valid in kf.split(df_train):
print(_train, _valid)
まずはKFoldの動作を確認するために上記のようなコードを書いてみました。KFoldの働きは、元データを「n_splits」で指定した数の分に切り分けて、トレーニングデータと検証データに切り分けてくれます。
なお、上の実行結果からわかるように、KFoldが出力する値はindexの値です。この値でデータにフィルタをかけて使用します。
図の左側に並んでいるのは「_train」の内容でトレーニングデータに振り分けたindexの値です。右側は「_valid」の内容で、検証用データに振り分けたindexの値です。上から1回目、2回目・・・5回目と振り分けた結果になっています。
冒頭で出てきたクロスバリデーションの図と比較するとわかりやすいのですが、1回目では検証データが0から始まっており、2回目は10800から始まっています。冒頭のイメージ図のように、検証用データが毎回ずれて、5回とも別の部分の抜き出している状態が確認できると思います。
クロスバリデーションなしの場合
まずは比較用にクロスバリデーションを使用しないパターンを見てみましょう。今回はよく使用される「LightGBM」を使用します。
df_train = df.iloc[:50000, ]
df_eval = df.iloc[50000:54000, ]
lgb_train = lgb.Dataset(df_train.drop(['target'], axis=1), df_train['target'])
lgb_eval = lgb.Dataset(df_eval.drop(['target'], axis=1), df_eval['target'])
params = {
'objective' : 'multiclass',
'num_class' : 8,
'metric' : {'multi_error'},
'verbose' : -1
}
model = lgb.train(
params,
lgb_train,
valid_sets = [lgb_eval, lgb_train],
num_boost_round = 1000,
callbacks=[lgb.early_stopping(stopping_rounds=100)]
)LightGBM自体の解説は別記事を参照してください。今回は手動でデータをトレーニング50,000データ、検証データをそのあとの4,000データとしました。
今回は使い方の確認と効果の検証を実施するだけなので、EDAや特徴量エンジニアリングはしていません。このあたりも興味ある方は別記事を参照してください。
model_predict = model.predict(df_test.drop(['target'], axis=1), num_iteration=model.best_iteration)
model_predict_c = pd.DataFrame(np.argmax(model_predict, axis=1), columns=['predict'])
df_test = df_test.reset_index(drop=True)
ans = pd.DataFrame(df_test['target'], columns=['target'])
ans['predict'] = model_predict_c
len(ans.query("target==predict"))/len(ans)
トレーニング済みデータでテストデータの結果を予測しています。出力が各カラムの予測値で出てくるので、カテゴリーに変換するため、「np.argmax()」でカテゴリーに変換後、「predict」というカラム名でデータフレーム化し、トレーニングデータの答えと並べてみました。最終的に、答えと予測値が同じものの数をカウントし、全体の数で割って正答率を算出しています。
結果、72.1%正解しているようです。
ans.tail()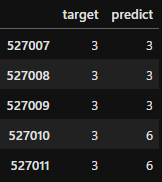
先ほどの予測値を答えを並べたデータの最後5行を表示してみました。確かに「target:正解」と、「predident:予測値」が違っているところがあります。
同条件でクロスバリデーションを実施
df_train_2 = df.iloc[:54000, ]
kf = KFold(n_splits=5)
ens = pd.DataFrame()
for fold, (_train, _valid) in enumerate(kf.split(df_train_2)):
X_train, X_valid = df_train_2 .iloc[_train,].drop('target', axis=1), df_train_2 .iloc[_valid,].drop('target', axis=1)
y_train, y_valid = df_train_2 .iloc[_train,]['target'], df_train_2 .iloc[_valid,]['target']
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid)
model_2 = lgb.train(
params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
callbacks=[lgb.early_stopping(stopping_rounds=100)]
)
model_2_predict = model_2.predict(df_test.drop(['target'], axis=1), num_iteration=model_2.best_iteration)
model_2_predict_c = pd.DataFrame(np.argmax(model_2_predict, axis=1), columns=[fold])
ens = pd.concat([ens, model_2_predict_c], axis=1)今度は「KFold」を使用してクロスバリデーションをしてみましょう。全体のコードは上記の通りですが、少しばらして解説していきます。
df_train_2 = df.iloc[:54000, ]
kf = KFold(n_splits=5)
ens = pd.DataFrame()1行目はトレーニングデータを最初の54,000データ取り出しています。今回はトレーニングデータ、検証データを自動で分割してくれるので、その二つを合わせたデータを取り出しました。
2行目にKFoldを使用するためにkfを設定します。
3行目は各クロスバリデーションの予測結果を入れる入れ物として空のデータフレームを用意しておきました。
for fold, (_train, _valid) in enumerate(kf.split(df_train_2)):KFoldで5分割したデータをkfが5回返してくれますので、そのデータをforを使って解析を回します。foldにはenumerateの値、_train、_validにはそれぞれkfの値をsplitで分割してトレーニングデータ、検証データを入れます。
以降、forで回す内容です。
X_train, X_valid = df_train_2 .iloc[_train,].drop('target', axis=1), df_train_2 .iloc[_valid,].drop('target', axis=1)
y_train, y_valid = df_train_2 .iloc[_train,]['target'], df_train_2 .iloc[_valid,]['target']
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid)trainデータ、validデータを毎回入れ替えます。「df_train_2」のデータから、ilocで使用する部分のみ取り出します。先ほど解説しているようにKFoldが返す値はindexの値なので、iloc[_train,]で該当するインデックスのデータを取り出します。
その後、それを毎回データセットに入れます。
model_2 = lgb.train(
params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
callbacks=[lgb.early_stopping(stopping_rounds=100)]
)ここは先ほど実施したLightGBMと同じです。モデル名は間違えないように変えています。ここに毎回データセットが変わったデータを入れてトレーニングします。
model_2_predict = model_2.predict(df_test.drop(['target'], axis=1), num_iteration=model_2.best_iteration)
model_2_predict_c = pd.DataFrame(np.argmax(model_2_predict, axis=1), columns=[fold])
ens = pd.concat([ens, model_2_predict_c], axis=1)ここはクロスバリデーションを使用していない時と同様、今回学習したモデルであるmodel_2で予測した結果をカテゴリーに変換し、「ens」データフレームに入れていきます。
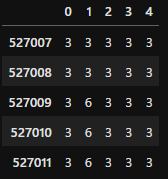
ensの内容を見てみると、先ほど間違えが見つかった最後のデータ、一部やはり「6」と予測している回がありますが、ほかの回ではただしい「3」と予測しているところが多そうです。
ens['ens'] = ens.mode(axis=1)[0]
ans = pd.concat([ans, ens['ens']], axis=1)
len(ans.query("target==ens"))/len(ans)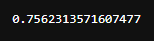
クロスバリデーションを使用していないパターンと同じように正答率を出したいので、まずはmodeで最頻値を出し、それを先ほどの結果をまとめていた「ans」のデータフレームの中に「ens」というカラム名で入れました。
その後同じ方法で正解率を出してみました。75.6%と、クロスバリデーションを使用していない場合に比べて3.5%向上しています。
ans.tail()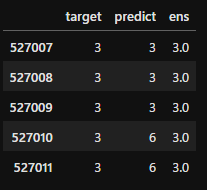
テストデータ最後の部分もこのように変わっています。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
クロスバリデーションについて説明してきました。アンサンブルやクロスバリデーションのような多数決式な方法は、一般的に正答率の向上が見込まれることがわかっています。
今回の内容をマスターし、モデルの精度向上に努めてください。





