画像の特徴量抽出は、機械学習や画像マッチングを成功させるうえで重要な工程です。慣れていない方のなかには、「どんな方法があるのかわからない」と悩んでいる方も多いのではないでしょうか。
そこで今回は、画像の特徴量抽出の主要なアルゴリズムを6つ紹介します。それぞれのアルゴリズムや適用例の解説を通じて、適切な使い分け方を理解できます。
機械学習を利用した画像認識や画像マッチングを理解したい方は、ぜひ最後までご覧ください。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
画像の特徴量抽出とは?
画像の特徴量抽出とは、画像内の物体や画像そのものを特定するための要素を取り出すことです。機械学習や画像マッチングにおいて必要になる工程です。
抽出される要素には、下記のような例が挙げられます。
- 輝度分布
- 色の出現率・分布・種類
- 物体の位置関係
- エッジ
特徴量抽出では物体そのものを取り出すのではなく、画像の拡大縮小や回転などの幾何学的変化の影響を受けずに、一意に識別できるピクセル情報へ落とし込みます。
また、画像の特徴量を抽出する方法は、「人為的手法」と「機械的手法」の2種類に大きく分けられます。人為的手法は人手で抽出アルゴリズムを構築する方法で、一方の機械的手法はコンピュータが自動的に抽出アルゴリズムを構築する方法です。
画像の特徴量は、抽出アルゴリズムによって大きく変わります。次の章から具体的な抽出アルゴリズムを紹介するので、適切な特徴量を取り出すためにもチェックしてみてくださいね!
画像の特徴量抽出のアルゴリズム|人為的手法
まず、画像の特徴量抽出の人為的手法について下記の3つを紹介します。
- Haar-Like特徴量
- HOG特徴量
- SIFT特徴量
人為的の意味は、数式を用いて画像から特徴量への変換プロセスを人が指定することを指します。では、それぞれの適用例やアルゴリズムの内容を見ていきましょう!
Haar-Like特徴量
Haar-Like特徴量とは、画像における明暗差の集合を特徴量とする特徴量抽出手法です。画像内で明暗差が出やすい「顔画像」の検出分野で、一般的な手法です。
 引用:コンピュータビジョン分野における機械学習 (2. 顔検出・人検出)/Global walkers
引用:コンピュータビジョン分野における機械学習 (2. 顔検出・人検出)/Global walkers
具体的には、画像内の特徴量を抽出したい部分に探索窓を配置し、探索窓内で「Haar-Likeパターン」と呼ばれる矩形の配置・サイズ・種類を変えて、画像内の明暗差を抽出します。
そして、Haar-Likeパターンの黒領域のピクセル値の和から、白領域のピクセル値の和の差を取った値を特徴量とします。
適当な特徴量が得られるまで、さまざまなHaar-Likeパターンによる特徴量抽出を繰り返します。
Haar-Like特徴量のアルゴリズムは、和差算のみであるため、ほかの手法と比較して計算量が多くありません。
そのため、迅速な処理が必要な「リアルタイムの位置検知システム」で利用されるケースも増えてきています。
HOG特徴量
HOG特徴量とは、グレイスケール画像内の輝度の勾配方向の分布に注目した特徴量です。具体的には、下記の手順で各ピクセルの輝度勾配をヒストグラム化して特徴量を抽出します。
- 画像全体の輝度勾配と強度を算出
- セルごとに勾配強度の重みづけをしながら勾配方向ヒストグラムを作成
- ブロックごとに正規化し結合したものを特徴量とする
下記の図がHOG特徴量の一連の工程です。
 引用:知っておきたいキーワード 局所画像特徴量/HOG特徴量の計算方法
引用:知っておきたいキーワード 局所画像特徴量/HOG特徴量の計算方法
初めに、画像全体の輝度の勾配方向と強度を算出します。次に「セル」と呼ばれる正方形領域へ分割し、セル内部で勾配方向ヒストグラムを作成します。勾配方向ヒストグラムでは、セル内のエッジ成分の方向を抽出することが可能です。最後に、セル内を小さな正方形のブロックへ分割し、勾配方向ヒストグラムを正規化します。
HOG特徴量は、セルごとに輝度の勾配方向ヒストグラムを作成するので、物体の形状情報やエッジの特徴を抽出するのが得意です。そのため、画像間で大きさが一定の物体に対しては回転や明度の変化に影響しない特徴量を抽出できることから、人物の検出や移動物体の認識で使われます。
SIFT特徴量
SIFT特徴量とは、特徴点の検出工程と特徴量の記述工程の2段階に分けて抽出する手法です。具体的には、下記の流れで画像の特徴量を抽出します。
- ガウシアンフィルタでスケールの異なる平滑化画像を作成
- 平滑化画像間の差分画像に対して極値探索で特徴点を絞り込む
- 各特徴点の勾配方向ヒストグラムを作成し方向を決定
- 特徴点の方向を基準に特徴量の勾配方向ヒストグラムを作成
下記の図がSIFT特徴量の一連の工程です。
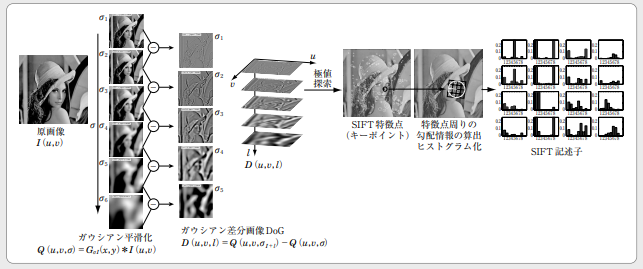 引用:知っておきたいキーワード 局所画像特徴量/SIFT特徴量の計算方法
引用:知っておきたいキーワード 局所画像特徴量/SIFT特徴量の計算方法
特徴点の検出工程とは、画像内で空間的な変化量が大きく、エッジやテクスチャなどの情報量を多く含む点を絞り込む工程のことです。
初めに、ガウシアンフィルタを使って元画像からさまざまなスケールの平滑化画像を作成します。k倍差ある2枚の平滑化画像間の差分を求めたあと、差分画像の極値を探索し、特徴点としてふさわしくない点を削除します。残った極値点が特徴点です。
上記の画像で例えると、特徴点の検出工程はスケールが大きくなっても変化が少ない背景よりも、形が大きく変わる帽子部分が特徴点として採用される仕組みです。
特徴量の記述工程とは、前工程で求めた特徴点に基づいて、勾配方向の決定と特徴量の勾配方向ヒストグラムの作成を行う工程です。
まず、特徴点周辺の輝度の勾配方向と強度に基づいて、勾配方向ヒストグラムを求めます。求めたヒストグラムで、強度が最大値の80%を超える勾配方向を「特徴点の方向」として採用します。強度を求める際は下記のように特徴点のガウシアンフィルタのスケールを用いて重み付けすることで、特徴点に近い特徴量を強調できるように処理を行うのがポイントです。
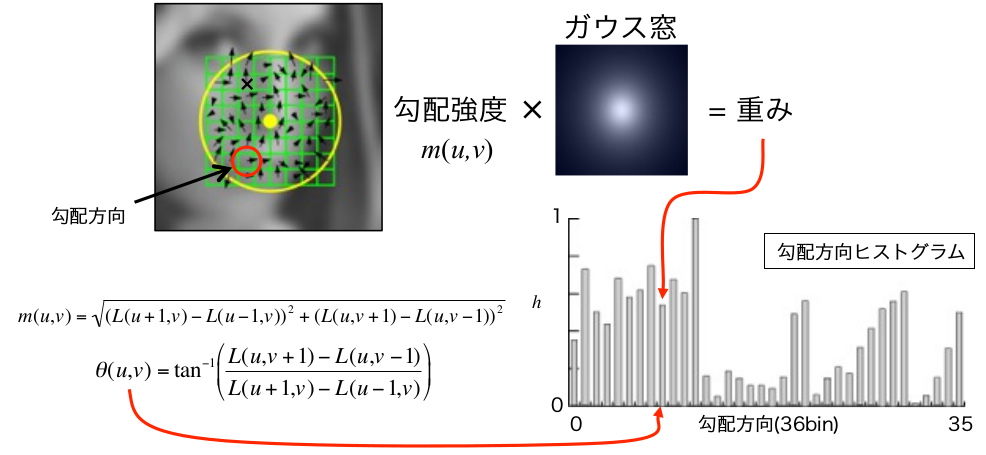 引用:
引用:次に、決めた特徴点の方向を基準に、特徴量の勾配方向ヒストグラムを再構築します。具体的には、下記のように特徴量を記述する領域(緑のマス目)を特徴点の方向(赤矢印)に合わせて回転させて、領域内を小さなセルへ分割し各セルごとに勾配方向ヒストグラムを作成します。
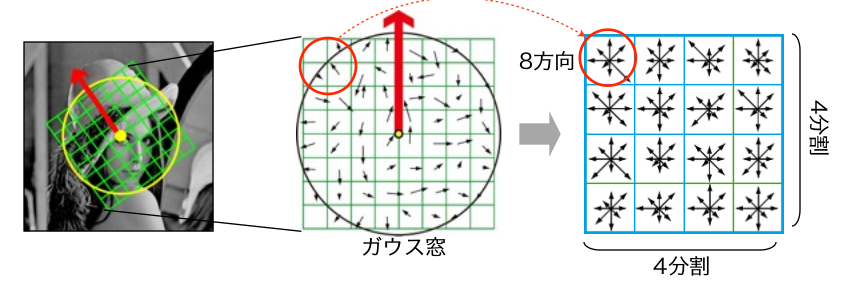 引用:
引用:算出した勾配方向ヒストグラムをベクトル化したものが、SIFT特徴量です。
SIFT特徴量は特徴点の方向に合わせて特徴量を記述するため、物体の位置情報の抽出が可能です。そのため、画像間で物体が回転したり、角度が変わったりしても影響を受けないため、SIFT特徴量は物体認識のタスクで幅広く利用されています。
画像の特徴量抽出のアルゴリズム|機械的手法
続いて、画像の特徴量抽出の機械的手法について下記の3つを紹介します。
- CNN
- VGG
- ResNet
上記はすべて機械学習・ディープラーニング手法です。ディープラーニングを含む機械的手法では、画像から特徴量への変換プロセスをコンピュータが自動的に決定します。
ディープラーニングは「学習」のイメージが強いですが、実は学習器と特徴量抽出器に分かれており、特徴量の抽出器のみでも使用可能です。
ディープラーニングを特徴量抽出器として使う場合には、転移学習と呼ばれる学習済みのモデルを別のタスクへ適用するケースが大半です。学習済みモデルの場合には、特徴量抽出器のパラメータが最適化されているため、より信頼性の高い特徴量を抽出できます。
では、画像の特徴量抽出ができる機械的手法のアルゴリズムの内容や適用例を順番に見ていきましょう!
CNN
CNN(畳み込みニューラルネットワーク)とは、画像の特徴量を畳み込み演算とダウンサンプリング操作によって抽出する手法です。下記図の「FEATURE LEARNING」にあたる部分が、CNNの特徴量抽出工程です。
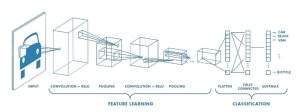 引用:今時のエンジニアが知っておくべきディープラーニングの基礎知識/Codexa
引用:今時のエンジニアが知っておくべきディープラーニングの基礎知識/Codexa
具体的には、下記の流れで特徴量を抽出します。
- 畳み込み演算部:フィルタと画像との畳み込み演算を行い「特徴マップ」を作成
- ダウンサンプリング部:ブロックごとに特徴マップの最大値を算出し画像サイズを小さくする
まず、正方形のフィルタを用意し、画像の左上から順番にスライドさせて畳み込み演算を行います。下記の図は、3×3のフィルタを1ピクセルずつスライドさせた場合の畳み込み演算です。
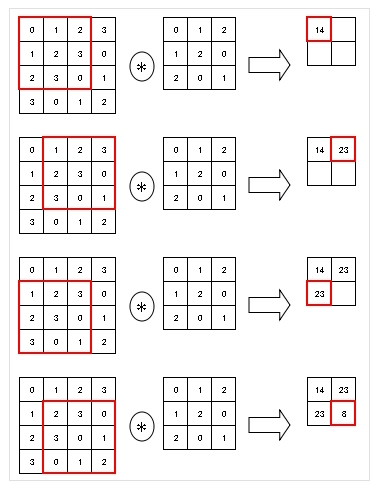 引用:ディープラーニングを基本から学ぶ Part5 畳み込みニューラルネットワーク/Qiita
引用:ディープラーニングを基本から学ぶ Part5 畳み込みニューラルネットワーク/Qiita
フィルタの大きさとスライド幅は人が指定するケースが多いですが、グリッドサーチなどハイパーパラメータ探索手法によって自動的に設定することも可能です。フィルタの大きさは3×3・5×5・7×7、スライド幅は1が代表的で、細かく特徴量を抽出できるように設計されます。
また、フィルタの重み係数は学習により最適化され、エッジなどの重要な部分を抽出できるように画像データ群に基づいてコンピュータが自動で決定します。
次に、特徴マップに対してダウンサンプリングを行います。CNNのダウンサンプリングとは、特徴マップのサイズを演算により小さくする処理です。演算には、下記図の最大値プーリング(上側)と平均値プーリング(下側)がよく使われます。
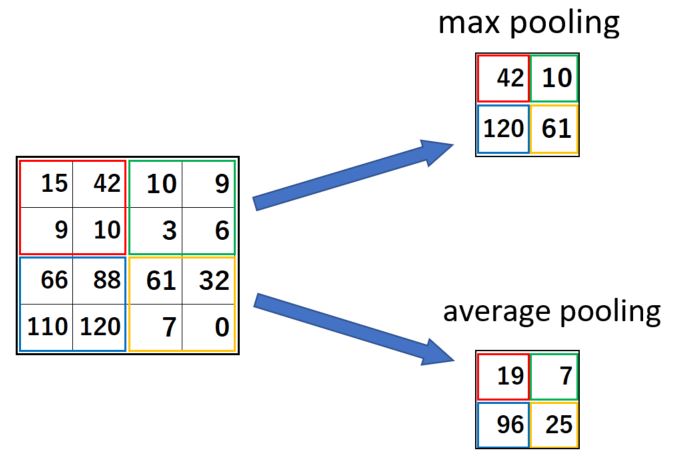 引用:CNN(畳み込みニューラルネットワーク)の仕組み/eF-4 developer & creator blog
引用:CNN(畳み込みニューラルネットワーク)の仕組み/eF-4 developer & creator blog
最大値プーリングとは、ブロック内の最大値をとる処理です。最大値プーリングは、最も重要と判断されたピクセル情報が抽出されるため、うまく検出できた場合にはエッジ情報が強調された特徴量が得られます。
一方で、平均値プーリングとはブロック内の平均値を求める処理です。特徴量成分をエッジとエッジ以外の部分を平均化するため、全体的にエッジが集中している部分以外は、全体的にぼやけた輪郭線になります。
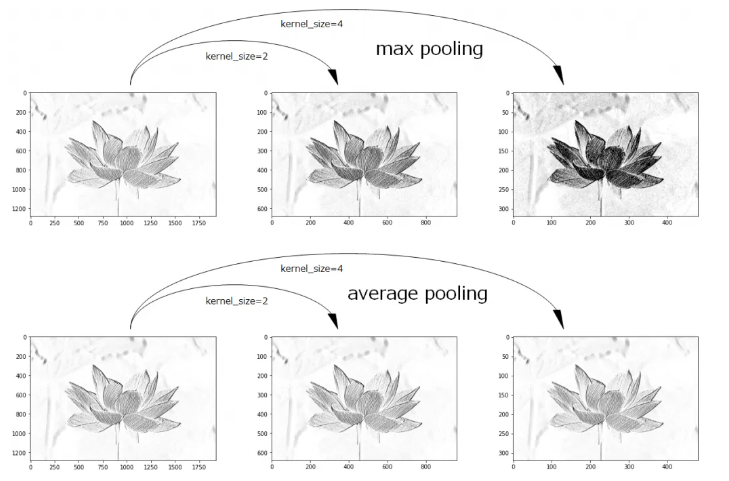 引用:畳み込みニューラルネットワークの理論とPyTorchによるLeNetの実装/AGIRobots Blog
引用:畳み込みニューラルネットワークの理論とPyTorchによるLeNetの実装/AGIRobots Blog
いずれのダウンサンプリングも、ピクセル情報を削除したり、平均化したりすることで、位置情報に対するロバスト性を高める役割を持ちます。
CNNでは、畳み込み演算部で重み付けフィルタにより周辺のピクセル情報を加味しながら特徴を抽出し、ダウンサンプリング部で位置情報の削除を行っているのです。
2段階の処理により、方向や大きさの異なる画像でもマッチングできる特徴量を作成できます。そのため、CNNは医学・自動運転・製造ラインなど幅広いケースの画像認識タスクで活用されています。
なお、CNNの畳み込み演算やプーリングの詳しい説明は、下記を参考にしてくださいね!

VGG
VGGとは、3×3の小さなフィルタと大量のフィルタ数が特徴的なCNNの発展手法です。VGGでは16層と19層のモデルがありますが、特徴量抽出器としてよく使われるのは16層です。
下記図が、16層のVGGの全体像です。
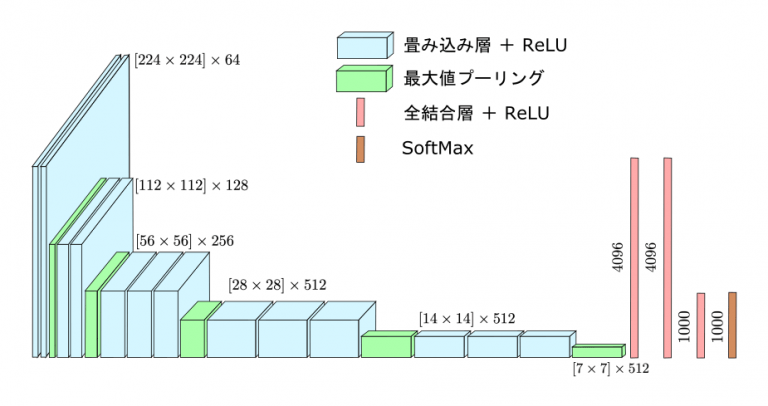 引用:VGGNet: 初期の定番CNN/CVMLエキスパートガイド
引用:VGGNet: 初期の定番CNN/CVMLエキスパートガイド
VGGでは畳み込み演算を2〜3回繰り返したあとに、最大値プーリングを1回行うことで、特徴量を抽出します。小さなフィルタで細かく特徴量を抽出することで、必要以上にピクセルのエッジ情報などを削ぎ落とさないように工夫しているのです。
また、1つの畳み込み演算部しかないCNNに対して、13層あるVGGではより解像度の高い特徴マップを作成できます。
VGGは、フィルタのパラメータ数が多いため、特徴量の抽出スピードはほかのCNN系のモデルと比較して早くありません。そのため、「リアルタイム物体検出」ではあまり使われませんが、1,000クラスの画像分類タスクなど確実性が必要なケースではよく利用されています。
ResNet
ResNetとは、入力画像との差分を学習することで、詳細な特徴の抽出ができるCNNの発展手法です。
ResNet以前の多層CNNでは、一定以上層を増やすと学習勾配が消失し、層の後半になるにつれて初期で抽出できていた特徴量をうまく引き継げない課題がありました。そのため、VGGでは最大でも19層が限界でしたが、ResNetでは入力値の渡し方を工夫することで152層まで多層化に成功しています。
下記図が、34層のResNetの全体像です。
 引用:ResNet (Residual Network) の実装/AI drops
引用:ResNet (Residual Network) の実装/AI drops
特徴的な半円を描いている工程は、残差ブロックと呼ばれます。残差ブロックとは、まとめられた2層の畳み込み層をスキップ接続により無視できる層のことです。
従来モデルのように畳み込み演算の出力「F(x)」を次の層の入力として渡すのではなく、下記のようにスキップ接続により渡される入力と畳み込み演算の出力との差分「F(x)+x」を渡していきます。
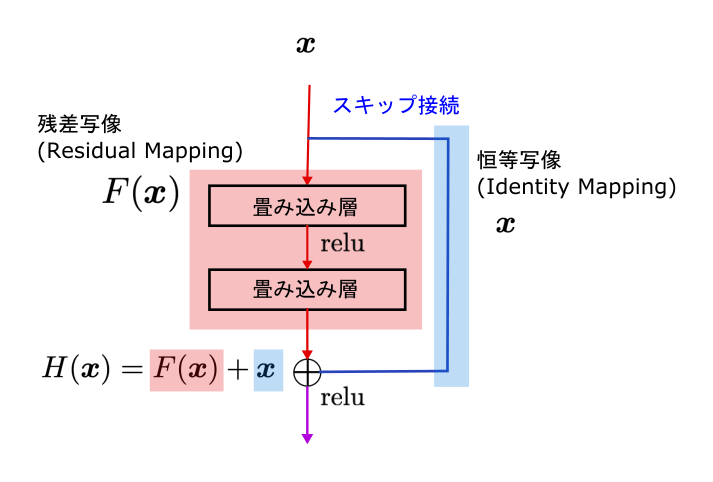 引用:残差接続 (residual connection) [ResNet]/CVMLエキスパートガイド
引用:残差接続 (residual connection) [ResNet]/CVMLエキスパートガイド
残差ブロックを活用した差分学習により、初期で抽出できた特徴量を後ろの層まで引き継ぐことができるのです。
ResNetはCNN系のモデルのなかでも特に高度な特徴量抽出が可能なため、特徴量抽出器として転移学習が必要なケースで広く使われています。
【コード付き】画像の特徴量抽出をSIFT法で実装する方法
では、実際の画像から特徴量を抽出してみましょう!今回のテーマは、SIFT特徴量で「Lenna」と呼ばれるカラー画像から特徴量を抽出する実装方法を理解することです。
具体的な手順は下記の通りです。
- 各種ライブラリのインポート
- 画像の読み込み
- SIFT特徴量で特徴量抽出
- 元画像と特徴量抽出画像を描画
では、下記を参考に実装してみましょう!
# インポート
import cv2
from matplotlib import pyplot as plt
# 画像の読み込み
gray_org_img = cv2.imread('/Lenna.png',0)
# 画像からSIFTを用いて特徴量を抽出
sift = cv2.SIFT_create()
keypoints = sift.detect(gray_org_img, None)
# 特徴点の表示
img_sift = cv2.drawKeypoints(
gray_org_img,
keypoints,
outImage=None,
color=None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,
)
# 元画像描画
plt.subplot(121),plt.imshow(gray_org_img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
# 特徴量抽出後の画像描画
plt.subplot(122),plt.imshow(img_sift,cmap = 'gray')
plt.title('Feature Extraction Image'), plt.xticks([]), plt.yticks([])
plt.show()
SIFT特徴量が実装できれば、下記のように特徴量抽出した画像を得られます。

OpenCVを使えば、数行程度で複雑なSIFT特徴量のアルゴリズムを構築可能です。ほかにも画像の特徴量抽出用のアルゴリズムモジュールが用意されているので、特徴量抽出に興味がある方はOpenCVをチェックしてみてくださいね!

データサイエンスを学習するならTech Teacherで!

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
画像の特徴量抽出とは、画像内の輝度差やRGB情報を特徴量抽出アルゴリズムによって取り出すことです。特徴量抽出アルゴリズムは、下記のように人為的手法と機械的手法に分けられます。
| 人為的手法の例 | 機械的手法の例 |
|---|---|
| ・Haar-Like特徴量
・HOG特徴量 ・SIFT特徴量 |
・CNN
・VGG ・ResNet |
それぞれの手法はOpenCVやPythonでモジュール化されており、数行で実装できるものもあります。
今回紹介した内容に加えて、画像の特徴量抽出をもっと深く知りたい方には、「TechTeacher」がおすすめです!TechTeacherでは、画像処理やOpenCVに熟知した講師から、マンツーマンでレッスンを受けられるメリットがあります。
画像の特徴量抽出がうまくなりたい方や画像処理関連の悩みがある方は、お気軽にお問い合わせください。