
Kaggle(カグル)は機械学習関連のデータ分析コンペや議論が活発なコミュニティです。世界中からコンペに参加するエンジニアたちがお互いの手法を議論したり、データセットを分析したりと、Kaggleはデータサイエンスの大きな学び場となっています。
しかし、初学者の方は機械学習手法の知識はあっても、コンペの取り組み方がわからない場合があります。そこで本記事では、Kaggleのチュートリアルであるタイタニック号のコンペの始め方を解説します。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
Kaggleとは
Kaggleはデータ分析関連のコンペや、機械学習技術についての議論が盛んなコミュニティです。世界中からエンジニアや研究者など、データサイエンスに興味関心を持つ人々が集まり、企業が出した課題に対する精度を競います。
特徴
コンペではランキング上位になると、賞金が貰える場合があります。企業側としては、高精度なアルゴリズムや技術を公募形式で獲得できる一方で、ユーザー側としてはコンペへの参加を通じて、技術力の向上や賞金の獲得といったインセンティブが得られます。つまり、企業は外部の優秀な人材を活用でき、ユーザーはスキルと対価を共に高めることが特徴的です。
さらに、Kaggleには画像データ, 音声データ, テキストデータなど、様々なジャンルのデータセットが公開されていることも大きな特徴です。公開データセットでは、単にデータを提供するだけでなく、標準的な前処理方法や基本的な分析手法も示されています。
データサイエンスを学ぶための入門教材として最適な環境が整っており、初心者でも手軽に取り組むことができるため、実践的なスキルの習得に最適でしょう。
チュートリアル
Kaggleには初心者でも取り組みやすいチュートリアルが豊富に用意されています。特にタイタニック号生存者予測の「Titanic – Machine Learning from Disaster」というチュートリアルがおすすめです。
これは1912年に沈没したタイタニック号の乗客データで、機械学習を用いて生存者を予測する課題です。乗客の名前や性別、年齢などの基本情報に加え、チケットのクラスや部屋番号など様々なデータが含まれています。
このデータを利用して、生存と関連性が深い特徴量を見つけ出し、ランダムフォレストやXGBoostなどのアルゴリズムで予測モデルを作成します。データの前処理方法、特徴量エンジニアリング、モデル評価など、機械学習の基本的な一連の流れを体験できる有名なチュートリアルです。
豊富な解説記事やサンプルコードも公開されているので、自分でも手を動かしながら学習できます。初学者向けの簡単なノートブックから始めて、精度を向上させるテクニックなども習得していきましょう。
titanicコンペの始め方
ノートブックの作成
URL:https://www.kaggle.com/competitions/titanic
まずはKaggleのアカウントを作成し、ログインした後にコンペに参加するボタンを押しましょう。
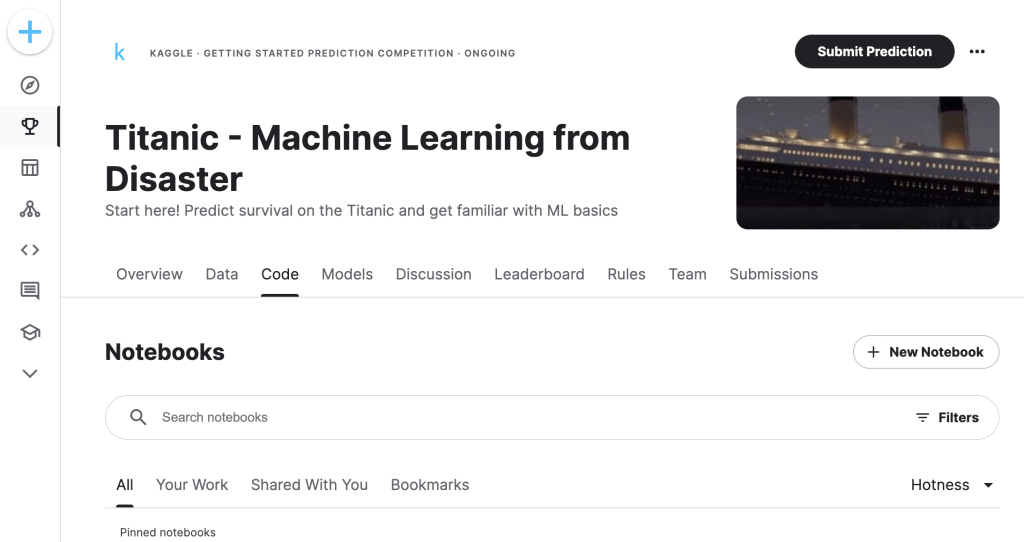
次に、Codeの欄から「+ New Notebook」で新しくノートブックを作成します。コンペのサイトからノートブックを作成することで、自動的にデータセットが用意されるため、おすすめな手順です。
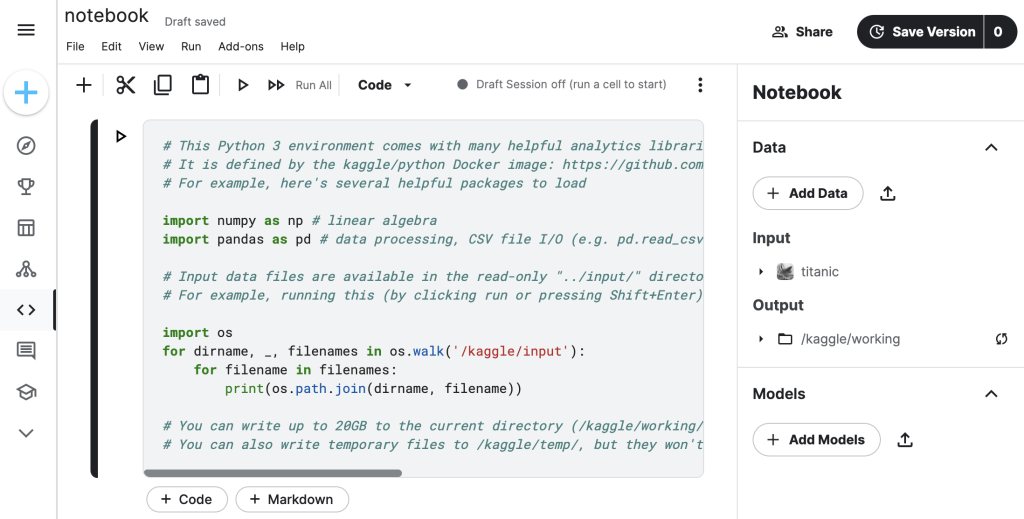
作成されたノートブックにはデフォルトでコードとコメントが記載されていますが、これにはデータ保存やライブラリについての説明が記載されています。では最後に、今回の実装に利用するライブラリの読み込みを記載しておきましょう。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineデータセットの読み込み
データセットを読み込む方法を見てみましょう。Kaggleで作成したノートブックでは、次のようなコードによって、データセットの読み込みが簡単に実装できます。
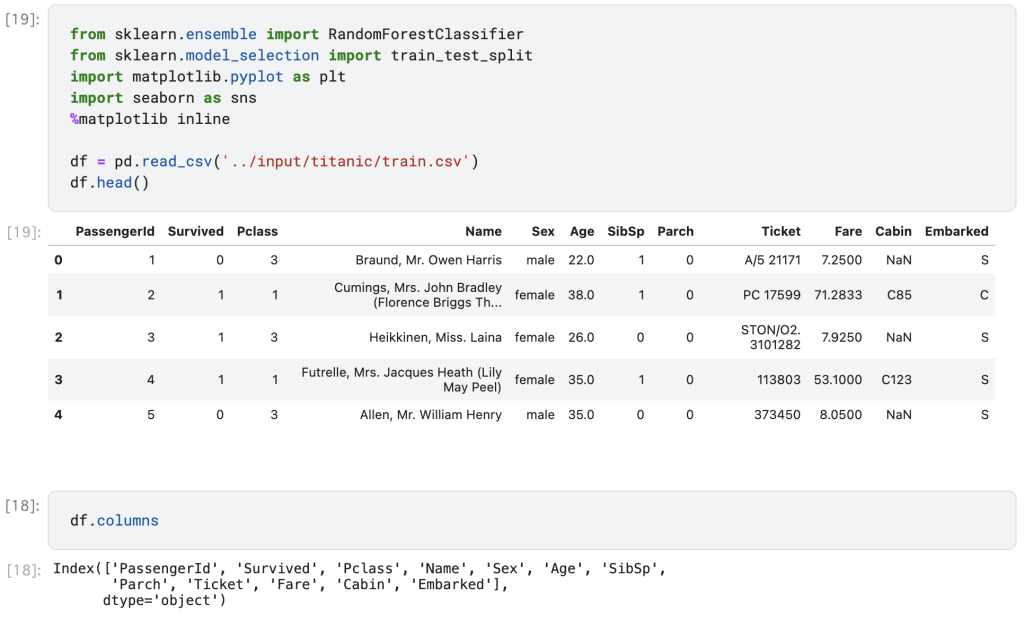
機械学習ライブラリであるscikit-learnとmatplotlibとseabornというデータ可視化ライブラリをインポートしています。head()メソッドでは、データの先頭部分が確認できるので、おすすめです。columnsプロパティでは、データにある項目を一覧で確認でき、これらが乗客の情報です。
データの分析
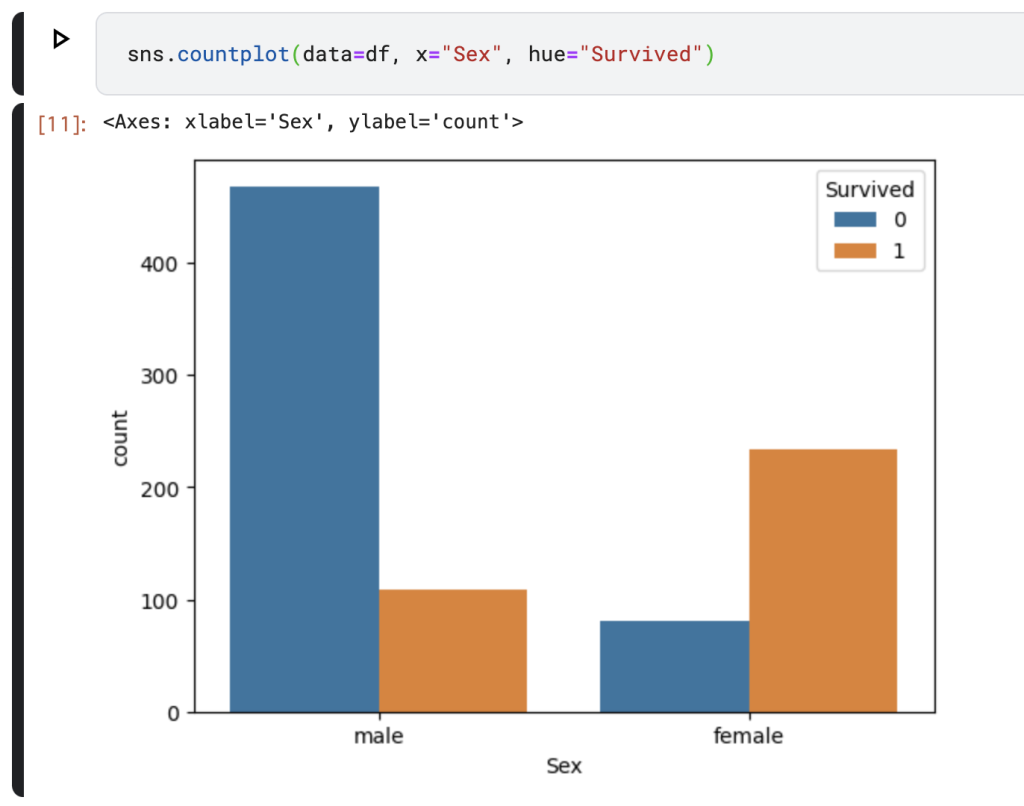
データの可視化例として、性別ごとの生存率を比較してみましょう。”Survived”は0が死亡、1が生存を示す値なので、明らかに女性の方が生存比率が高いことが読み取れます。有名な話ですが、タイタニック号では男性よりも女性と子供を優先的に救命ボードに乗せたことでこのような結果だと考えられています。
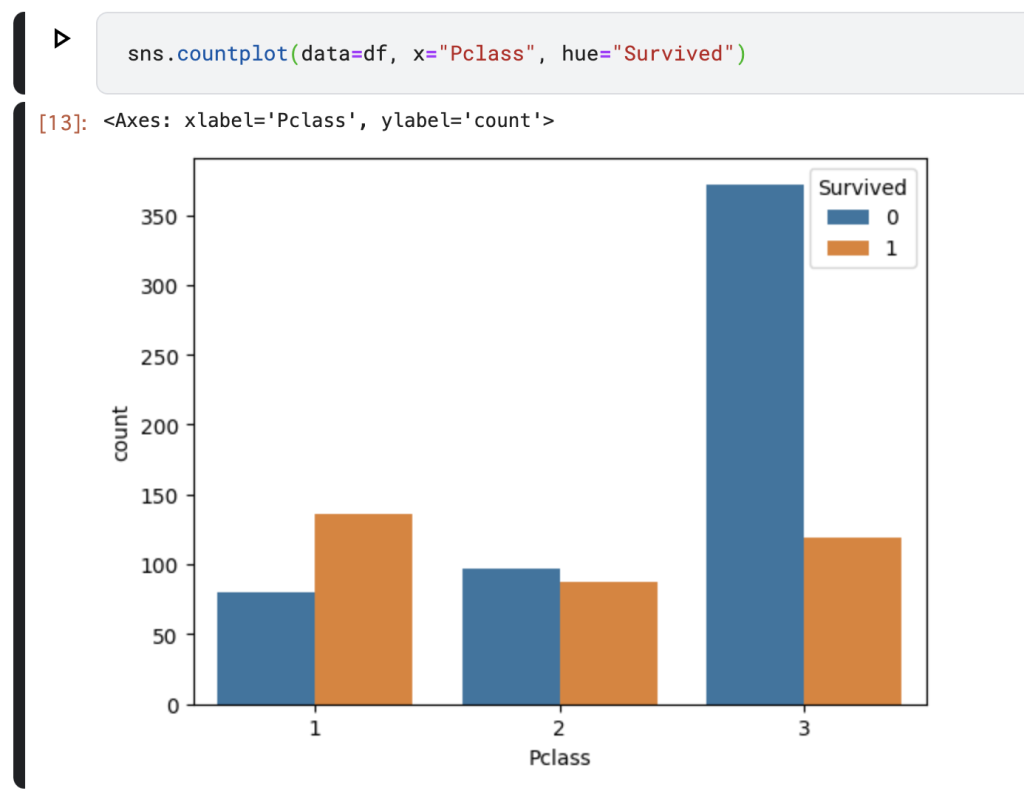
さらに乗客のチケットクラスと生存の関係も見てみましょう。上位チケットクラスほど生存確率が高い結果が得られていることがわかります。これは上級チケットの客室が船体の上の方にあり、また救命ボートへのアクセス優先順位が高かったことが影響していると考えられます。
このように、データには生存率に影響を与える項目があり、うまくデータを活用することで、ある程度は乗客が生存したかを予測できるとわかりますね。
機械学習モデルの実装
タイタニック号の乗客のデータから「生存したか」を予測するために、機械学習アルゴリズムの一つであるランダムフォレストを利用した例を見てみましょう。実は、読み込んだデータをそのまま予測に利用することはできません。
これは、文字列データが含まれていることが原因で、今回は簡単にするためにその列を削除します。データの可視化で見たように、文字列のデータにも意味はありますので、性別だけはラベルエンコーディングで数値に変換しましょう。
さらに、ランダムフォレストでは欠損値(NaN)が含まれると学習が不可能です。欠損値を値の平均値で補完しておきます。以上の前処理をprocess_df()で実装して、データを読み込むには次のように記述できます。
train_test_split()は、モデルの過学習を調べるために利用される学習用とテスト用のデータ分割に必要です。
# 欠損値の補完, ラベルエンコーディング, 列の削除
def process_df(df):
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Sex'] = df['Sex'].map({'male':0, 'female':1})
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df = df.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)
return df
# データセット読み込み
df_train = pd.read_csv('../input/titanic/train.csv')
df_train = process_df(df_train)
df_test = pd.read_csv('../input/titanic/test.csv')
df_test = process_df(df_test)
# 特徴量と目的変数に分割
X_train = df_train.drop(['Survived'], axis=1)
y_train = df_train['Survived']
# データを学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)では、ランダムフォレストでのモデル実装を行いましょう。scikit-learnライブラリでは様々なモデルが用意されており、簡単に機械学習アルゴリズムを実装できます。以下のプログラムのように、モデルの定義と学習にはたったの2行で済むため、非常に便利なライブラリです。また、結果の出力はテストデータに対する予測なので、注意しましょう。
# モデルの学習と評価
model = RandomForestClassifier()
model.fit(X_train , y_train)
print(f"score: {model.score(X_test, y_test)}")
# 結果の出力
y_pred = model.predict(df_test)
output = pd.DataFrame({"PassengerId": df_test["PassengerId"], "Survived": y_pred})
output.to_csv('submission.csv', index=False)実行ごとに結果は異なりますが、コンソール上に「score: 0.7932960893854749」のように出力された場合は成功です。エラーが起きた場合は、ライブラリの読み込みや、コードに誤りがないか確認してみましょう。
コード全体
最後に、今回実装したコード全体を再掲載します。コピーしてノートブック上で実際に動かしてみましょう。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 欠損値の補完, ラベルエンコーディング, 列の削除
def process_df(df):
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Sex'] = df['Sex'].map({'male':0, 'female':1})
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df = df.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)
return df
# データセット読み込み
df_train = pd.read_csv('../input/titanic/train.csv')
df_train = process_df(df_train)
df_test = pd.read_csv('../input/titanic/test.csv')
df_test = process_df(df_test)
# 特徴量と目的変数に分割
X_train = df_train.drop(['Survived'], axis=1)
y_train = df_train['Survived']
# データを学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# モデルの学習と評価
model = RandomForestClassifier()
model.fit(X_train , y_train)
print(f"score: {model.score(X_test, y_test)}")
# 結果の出力
y_pred = model.predict(df_test)
output = pd.DataFrame({"PassengerId": df_test["PassengerId"], "Survived": y_pred})
output.to_csv('submission.csv', index=False)チュートリアルの次に
まずは今回扱ったランダムフォレストや決定木といったアンサンブル学習をさらに詳しく学ぶことがおすすめです。特徴量も利用しなかった項目を扱うために、欠損値を補完したり、ラベルを数値に変換する作業を加えることも学びとなるでしょう。
次のステップとして、新たなデータセットで幅広い問題設定にチャレンジしていくことも重要です。画像認識や自然言語処理といった分野のコンペに参加することで、機械学習全体の流れを体感できます。
さらに他の機械学習ライブラリ(TensorFlowやPyTorchなど)を学び、深層学習による予測なども効果的です。チュートリアルが終わってからは、Kaggleの議論や上位の解法を参考にして、精度向上を目指してみてください。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
Kaggleは機械学習関連のコンペが開催されており、世界中から精度の高い手法を議論し合えるコミュニティです。そのチュートリアルとして有名なtitanicコンペの始め方や、モデルの実装を体験できましたね。今回利用したアルゴリズムはランダムフォレストですが、他にもXGBoostやLightGBMといったブースティング系の手法が上位のスコアを示すことが多いです。Kaggleのノートブックでは、様々な手法が実装された例があるため、それらを参考にしてみてください。





