

ロジスティック回帰を知っていますか? 軽量で動作も早く、使ったことがある方も多いと思いますが、その反面
実装の方法がよくわからない
結果の読み方がよくわからない
という人も多いのではないでしょうか。今回はロジスティック回帰の実装部分を中心に、実際にコードを追いながら確認していきたいと思います。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
ロジスティック回帰とは
ロジスティック回帰は「回帰」という名前がついていますが分類の手法になります。その名の通り、ロジット変換を行って重回帰分析に落とし込み、解析結果をロジスティック変換を行うことにより該当クラスに該当するかの確率を出すことによりクラス分けを行っています。
このあたりのことや統計的な意味や算出方法に関しては以下の記事で詳しく説明していますのでそちらを参照してください。今回はPythonで実装する方法と結果の見方に絞って解説していこうと思います。

また、基本的にはロジスティック変換時にシグモイド関数を用いて2クラスに分類しますが、変換方法で多クラス分類に拡張することは可能です。今回は基本形の2クラス分類の例を見ていきましょう。
今回は重回帰分析結果をロジスティック変換すると確率が出てくる、というところだけ認識しておいてください。
ロジスティック回帰で何ができるの?
ロジスティック回帰は先ほど分類のためのモデルと書きましたが、複数の説明変数からクラス分類するモデルですので
- 購買予測
- 病気の予測
の様に、「なる」、「ならない」などの分類問題に対して使用することが可能です。
Pythonでロジスティック回帰を実装する
ではirisデータセットを使用して実際にロジスティック回帰を実装してみましょう。
データセットの準備
データセットは「scikit-learn」の「irisデータセット」を使用します。まずはデータを加工していきます。
irisデータセットのtargetは
- 0:setosa:ヒオウギアヤメ
- 1:versicolor:ブルーフラッグ
- 2:virginica:アイリス・バージニカ
という3種類の目的変数を持っており、「target」のカラムにデータが入っています。今回は2値分類をしたいので、この中の「2:virginica:アイリス・バージニカ」に該当するデータを削除して2種類のtargetを分類していきたいと思います。
また、この目的変数を説明するための説明変数として
- sepal length (cm):がくへんの長さ
- sepal width (cm):がくへんの幅
- petal length (cm):花びらの長さ
- petal width (cm):花びらの幅
の4つの情報を持っています。この情報をもとにロジスティック回帰を行っていきたいと思います。
まず、データフレーム形式にして、データの件数を確認すると、150件データがあります。
import pandas as pd
from sklearn.datasets import load_iris
#irisデータを読み込む
iris = load_iris()
#説明変数部分をデータフレーム形式にする
df = pd.DataFrame(iris.data, columns=iris.feature_names)
#目的変数部分を先ほどのデータフレームに追加
df['target'] = pd.DataFrame(iris.target, columns=['target'])
display(df.head(), df.shape)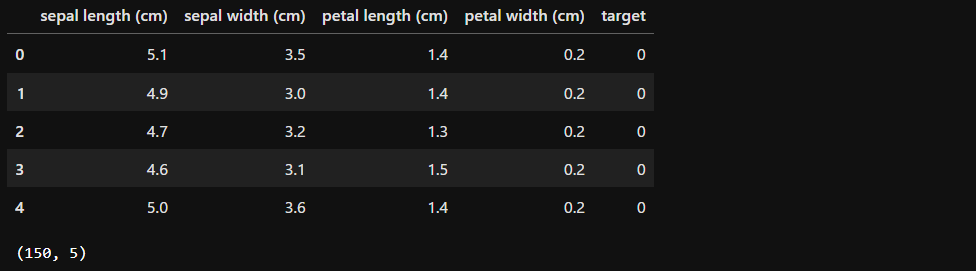
「targetが2でないデータ」という条件でデータを抽出し、データ数がちゃんと減っているかを確認します。
#「target」が「2」でないデータのみを採用する
df = df.query('target != 2')
df.shape
結果、targetが2のデータがなくなって、100件になりました。
ここで再度データをxとyに分割しておきます。
x = df[iris.feature_names]
y = df['target']その後、「train_test_split」でトレーニングデータとテストデータに分割してデータの準備完了です。
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0.2, random_state=8)
display(train_x.head(), train_y.head(), test_x.head(), test_y.head())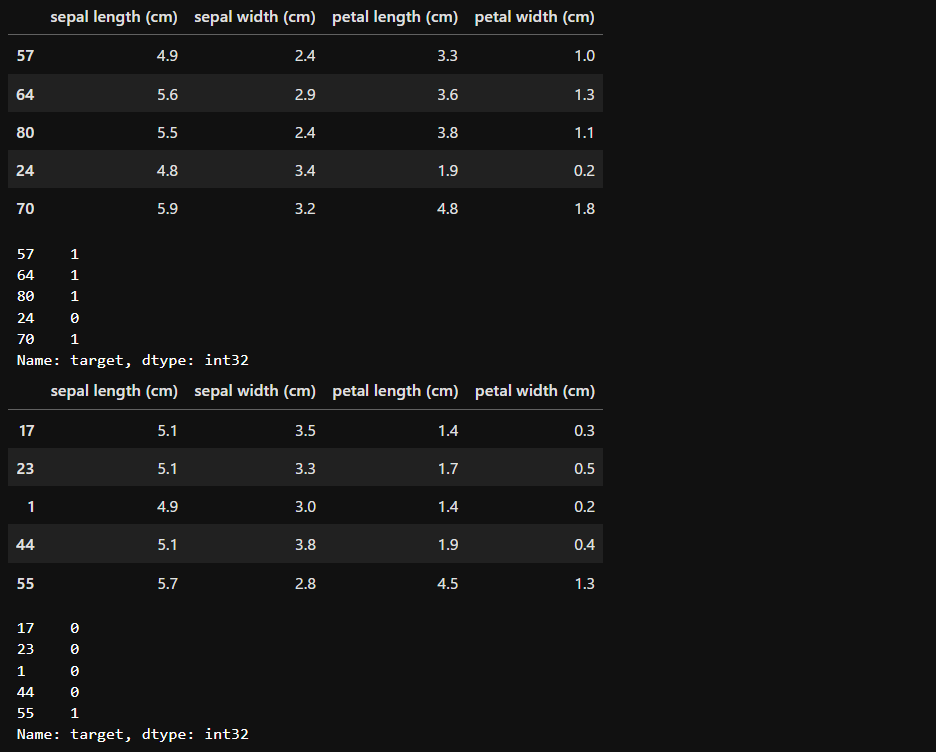
モデルを学習する
from sklearn.linear_model import LogisticRegression
#モデルを読み込む
model = LogisticRegression()
#モデルの学習
model.fit(train_x, train_y)結果を確認する
では、先ほどの学習結果より結果を確認していきましょう。
結果を予測する
pred = model.predict(test_x)
pred
accuracyの確認
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(test_y, pred)
accuracy
confusion_matrixの確認
from sklearn.metrics import confusion_matrix
pd.DataFrame(confusion_matrix(test_y, pred), columns=['pred0', 'pred1'], index=['y0', 'y1'])
test_xからの予測結果と、実際の結果test_yを比較することにより混同行列を表示します。見方は縦列に実際の正解ラベル、横軸にそれに対しての予測値を表示しています。
つまり、「y0」の横に並んでいるのはデータが実際に0であるもの、「y1」の横に並んでいるのは実際にデータが1であるものとなります。
それに対し、縦列は「pred0」の下にあるものが0と予測したもの。「pred1」の下にあるのが1と予測したものになります。
今回の場合は「0」が正解のものが13個あって、そのうち「0」と予測したものが13個、「1」と予測したものが0個、同様に「1」が正解のものが7個あって、そのうち「0」と予測したものは0個、「1」と予測したものは7個でした、ということです。
判別に用いた確率について
model.predict_proba(test_x)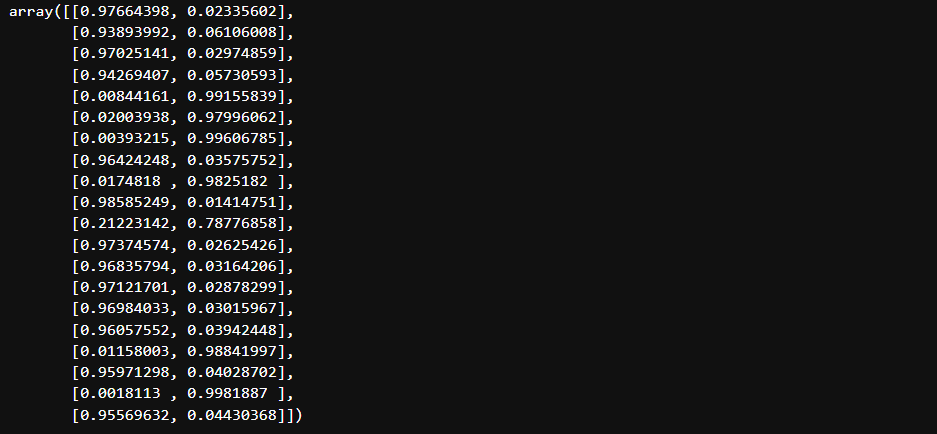
これより、各データにおける確率の高い方を書き出すと、
[0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0]
となり、「結果の予測」で出した予測結果と今回の結果があっているのがわかると思います。
計算結果の確認
ロジスティック回帰は重回帰分析結果をシグモイド関数で出力している結果であることは前述のとおりですが、実際にそうなっていることを確認していきましょう。
ロジスティック回帰の算出方法に関しては、詳しくは別記事で説明しようと思っていますので、そちらも参考にしてください。
回帰係数の確認
- y = b1*x1 + b2*x2 + b3*x3 + b4*x4 + c
model.coef_
切片の確認
model.intercept_
したがって、今回の重回帰分析の結果は
- y = 0.4047*x1 – 0.8350*x2 + 2.1907*x3 + 0.8807*x4 – 6.2061
ということになります。
手動で確率を計算してみる
では、それを計算してみましょう。
y = 0
#説明変数の数だけ処理を回す
for i, _ in enumerate(iris.feature_names):
#各項を計算
y += model.coef_[0, i]*test_x.iloc[0, i]
#切片を足す
y += model.intercept_
print(y)
今回はtest_xの一番最初の数値で計算してみました。

import numpy as np
1.0 / (1.0 + np.exp(-y))
その後、その値をシグモイド関数に入れてやります。結果、predict_proba()で予測した1件目のデータのカテゴリ1の確率と一致していることが確認できると思います。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回はPythonでのロジスティック回帰について確認してきました。非常に扱いやすいモデルなので、この記事を参考にぜひ活用していただければと思います。
また、冒頭でも案内していますが、ロジスティック回帰自体については別記事で細かく説明したいと思いますので、そちらも参考にしてください。




