

DeepLearningを学んでいくうえで物体検出をやってみたい!という方も多いと思います。しかし、始めるにあたって
何から手を付けてよいかわからない
実装するハードルが高そう
と思って困っている人、非常に多いと思います。今回は導入に関する説明と、簡単に実装ができるように準備されているYOLOV5を触って物体検知の初歩を確認し、今後使いたい物体検知モデルを独学できる基礎をつくっていきたいと思います。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
物体検出とは
そもそも物体検出ってなに?
物体検出とは、画像にうつっている特定の物体の位置と、数を検出するタスクになります。似た内容に物体認識がありますが、一般的に
- 物体認識:画像の中に何がうつっているかを判断する
- 物体検出:画像の中に何がどこにいくつ移っているかを検出する
という違いがあります。
どんなモデルがあるの?
具体的には有名なモデルとして以下の3つがあります。
- YOLO(You Only Look Once):今回触ってみるモデルです。いくつかのバージョンが出ていますが、今回は解説も多く、使用しやすいために実際に実装してみるのに最適なV5を使用してみたいと思います。Pytorchベースで作成されており、非常に簡単な操作で非常に高い精度を出すことが可能です。
- Faster-RCNN(Regional CNN):RCNNの改良版で比較的メモリ消費量や学習時間を抑えたモデルです。高精度に物体検出をすることが可能です。
- SSD(Single Shot MultiBox Detector):こちらも高精度な解析を行えるモデルです。小さい物体の検出にも強いモデルです。
YOLOを触って基礎を確認
では実際にYOLOV5を使用して、物体検出の基礎を確認していきましょう。
YOLOV5の準備
YOLOV5のダウンロードと展開
こちらのgithubよりYOLOV5をダウンロードします。右上緑色の[CODE]>[Download ZIP]の順にクリックするとダウンロードできます。
ダウンロードしたらZIPファイルを展開して、フォルダごと適当なフォルダにコピーしてください。
公式の説明に従ってgit cloneしても大丈夫です。
使用する環境の設定
YOLOV5を使用するにはpytorchやtorchvisionなど、いくつかのライブラリが正しくインストールされている必要があります。手動で確認しながらインストールすることも可能ですが、一度に必要なバージョンでインストールすることも可能です。
先ほどYOLOV5を展開したフォルダ、デフォルトでは「yolov5-master」となっていると思いますが、こちらのフォルダに移動し、以下のように実行してください。
pip install -r requirements.txtすると、自動的に必要なバージョンのライブラリがインストールされます。
フォルダの説明
意外とここが重要で、どこに何が入っているか、どこに何を入れるかをしっかり確認しておくとこの後の作業が、特にエラーが出た時非常に楽になります。
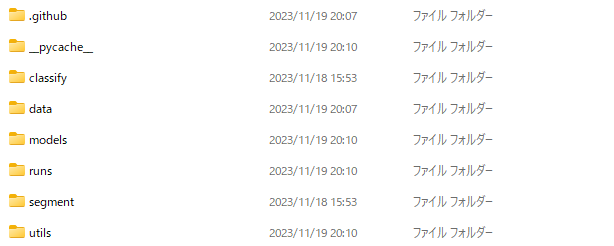
以下にフォルダの構成を示しておきます。なお
- [ ]・・・もとから存在するフォルダ
- ( )・・・必要に応じて作成するフォルダ(必ず同じ位置に作成する必要はありません)
としてフォルダを示します。
[data] 入力するデータをここに入れます。
├ [images] ここに入っているデータを推論に使用します。
├ (train) モデルを自分でトレーニングする際はここにデータを入れます。
├ (images) トレーニングに使用する画像データを格納します。
└ (labels) 画像と同じ名前で物体が映っている位置情報をラベルとして格納します。
└ (valid) 検証用データをここに入れます。
├ (images) 検証に使用する画像データを格納します。
└ (labels) 画像と同じ名前で物体が映っている位置情報をラベルとして格納します。[runs] 結果が格納されるフォルダです。(展開直後は存在しない)
├ [detect] 物体検出をした結果はこのフォルダに入ってきます。
├ [exp]
├ [exp2] 以下、物体検知を実行するたびにフォルダが増えます。
・・・
└ [train] 独自の検出対象を学習した場合はここに保存されます。(展開直後は存在しない)
├ [exp] 学習した情報がここに保存されます。
└ [weights] 学習済みの重みがここに保存されます。
├ [exp2] 以下、物体検知を実行するたびにフォルダが増えます。
└ [weights]
・・・まずはサンプル画像で物体検出をしてみる
まずはサンプル画像で実際に物体検出をやってみましょう。「yolov5-master」直下、「detect.py」が存在するフォルダで以下のように入力し、「detect.py」を走らせてみてください。
python detect.py --weights yolov5s.pt「–weights」部分で指定するのは学習済みの重みです。初期段階では
- yolov5n.pt
- yolov5s.pt
- yolov5m.pt
- yolov5l.pt
- yolov5x.pt
の5つが用意されています。下に行くほど重く、精度の良い重みになります。自分で学習した場合は、学習したものをここでしていして使用します。
検出に関しては、下の写真のようにエラーが出ずにバーが出て処理が進めば成功です。

最後の行に、「Results saved to runs\detect\exp」と記入がありますので、このフォルダをのぞきに行きましょう。すると、「data\images」に入っていたデータに検出された結果がついて保存されています。

左が元の画像、右が実施結果です。人とネクタイを正しく認識できています。画像は2枚あるので、もう一枚も確認してみます。

人とバスが正しく認識できていますね。
次はオリジナル画像で試してみる
もともと付属していたサンプル画像がうまくいったので、次はオリジナル画像で試してみます。先ほどのサンプルが置いてあった「data\images\」に画像をおいて、再度「python detect.py –weights yolov5s.pt」を実行してみます。

正しく人の部分が認識されています。
独自の物体を検出する
実際に物体検出をする際には学習済みモデルだけでなく、独自のものを検出したい場合の方が多いと思います。その際は、先ほど出てきた重みのファイルを自分で作り、それを使用して物体を検出します。
学習用データの準備
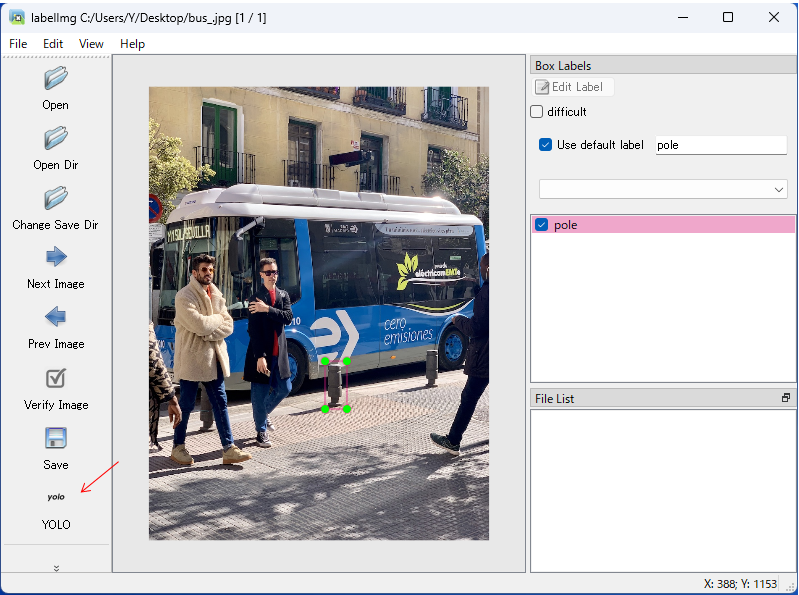
物体の学習をする際には、対象となる物体に「アノテーション」を行い、そのデータを学習します。アノテーションの例を以下に示します。
下の写真はフリーのアノテーションソフト「labelImg」の画像です。アノテーションはこのようなソフトを利用することで作成にかかる時間を短縮することが可能です。
なお、アノテーションデータはモデルによって形式が異なりますので、YOLOの場合はYOLOで使用する形で保存するようにします。labelImgの場合は図示部分を「YOLO」に変更して使用してください。
保存されたアノテーションデータは以下のような数値として、クラスNoと対象となる座標で示されています。
0 0.548765 0.658333 0.062963 0.098148学習用情報の準備
「トレーニングデータ」と「検証用データ」、「クラスの数」と「クラス名」を記入した「data.yaml」ファイルを準備します。ファイル名はなんでもかまいませんが、拡張子と記入の形式は合わせてください。
#data.yamlファイルの中身
#トレーニングデータと検証用データの場所
train: ./data/train/images/
val: ./data/valid/images/
#クラスの数と、各クラス名
nc: 1
names: [ 'Pole' ]学習の実行
python train.py --data data.yaml --weights yolov5s.ptモデルの学習も簡単にできます。「–data」に先ほど作成したデータの場所等を記載したyamlファイル、「–weight」に使用する重みファイルを指定します。今回は「yolov5s.pt」をベースに学習していますが、ここにすでに学習済みファイルを指定することも可能です。
この学習結果は上記で説明した「runs\train\exp\weight\」の中に格納されています。格納されるファイルは「last」と「best」です。スコアが最もよかった重みを使用したい場合は「best」の方を使用しましょう。
また、「runs\train\exp\」の中には学習時の情報が格納されていますので、合わせて参考にしてください。
データサイエンスを学習するならTech Teacherで!

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回はYOLOを中心に物体検出を見てきました。コードの内容やアルゴリズムは違いますが、実施する内容は大まかには同じですので、YOLOを習得して物体検出の学習に役立てていただければと思います。





