Pythonでデータ分析を始めようとしている方で、Pythonの基礎的な部分の学習を終えた後
- データ分析をするにはこれから何を覚えればいいの?
- Pythonを勉強し始めると範囲が広すぎて、結局何をすればいいのかわからない!
という方も多いのではないでしょうか。 今回はそんな方に向け、データ分析でよく使うライブラリを「まずはこの3つを覚えておきたい!」という視点で紹介していきます。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
Pythonの基礎
記事の内容に入る前に
今回の記事は、冒頭にも書いた通り「Pythonの基礎を勉強した」方に向けて書いています。Pythonの基礎がまだ自信がないな、という方は以下のサイトでまずはPythonの基礎に触れてみてください!
0から学ぶ【Python基礎】
Pythonの基礎を詳しく解説しています。各サイトでの学習とあわせてこちらも学習していくと効果的です。
以下の記事ではPython初学者向けのオススメ本とWebサイトの紹介をしています。


データ分析で使用するライブラリ
データ分析で使用するライブラリはいくつかありますが、特によく使用するものを解説していきたいと思います。以下に簡単に特徴を示します。詳細は後程解説します。
| ライブラリ | 特徴 |
| Pandas | データ分析用ライブラリ DataFrameというデータ分析に適した構造でデータを扱えるため、データ分析の際に非常によく使われる。 |
| Numpy | 数値計算用ライブラリ 行列計算を高速で実施してくれる。 |
| Matplotlib | グラフ表現のためのライブラリ データを可視化してくれる。 |
ライブラリのインポートは以下の記事でも扱っているので参考にしてください。

Pandas
Pandasはデータ分析用のライブラリです。DataFrameというデータ分析に適したデータ構造を提供してくれるため、データ分析時にはよく使用します。
また、ExcelやCSVのファイルを読み込み、書き込みができるため、非常に便利なライブラリになっています。
以下にデータ分析時に覚えておくべき使用方法を示します。

import
import pandas as pdpandasのインポートは上記のように行います。慣習的に「pd」と省略します。これは別名で省略してもよいのですが、一般的に「pd」とされるため、他人がすぐ理解できたり、何かを参照した際に「pd」となっていることが多く理解しやすいため、ぜひこの名称で省略するようにしましょう。
DataFrame
num = [[1, 2], [3, 4]]
df = pd.DataFrame(num)
df
これを実行すると上記のような表形式のデータが作られます。これをデータフレームといい、データ分析に必要な様々な機能が提供されています。
df.columns = ['col1', 'col2']
df
データフレームの「columns」を指定してやることにより、列方向のデータにタイトルをつけることが可能で、データが理解しやすくなります。
csvファイルの取り扱い
df.to_csv('test.csv')
!dir
データフレームに「.to_csv」とすることで、データフレームをcsv形式で保存することができます。
pd.read_csv('test.csv')
同様にcsvファイルを読み込む際は「pd.read_csv」で読み込みます。先ほど保存したものを読み込むと、上記のようにデータを読み込むことができています。
なお、「Unnamed:0」というカラムは、保存の際にカラムが自動保存されたもので、カラムを自動保存しないようにするには保存する際に以下のように保存します。
df.to_csv('test_2.csv', index=None)その後、先ほどと同じように読み込むとしたの図のように「Unnamed:0」列が消えています。

各列の集計
df.describe()
Pandasを利用すると、上記のようにデータフレームに「.describe()」とするだけで基本統計量を簡単に取得することが可能です。
df.corr()
また、データ分析の際に非常によく使用する相関係数行列も上記のように簡単に算出できます。
Numpy
Numpyは数値計算用のライブラリです。Ndarrayという構造を提供してくれるため、配列計算を非常に高速で実施してくれます。
以下にデータ分析時に覚えておくべき使用方法を示します。

import
import numpy as npNumpyのインポートはこのようになります。Numpyの略称は「np」とされることが多いです。
ndarray
array = np.array([[1,2,3], [4,5,6]])
array
ndarrayは「np.array」で作成することができます。
zeros = np.zeros(9)
zeros
「np.zeros」でゼロだけからなるndarrayを作成可能です。「()」内に指定した数字の分だけゼロの要素を作成できます。
np.zeros((3, 3))
「()」内の数字の指定の仕方を変えることで二次元配列になった数列で作成することが可能です。このようにして、数値の入れ物を先に作成してデータを解析していくことはよく行います。
np.zeros(((3, 3, 3)))
このように3次元にすることも可能です。
reshape
zeros.reshape(3, 3)
一度作成したndarrayの形を変更することも可能です。「reshape()」とすると指定した形のndarrayにすることが可能です。
flatten
array.flatten()
また、「.flatten()」とすることによりデータを一列に並べた形に変更できます。
簡単な演算
3 * array
3 + array
array + 3 * array
ndarrayは単体で数値をかけたり、足したり、ndarrayとndarrayを足したりすることも可能です。
Matplotlib
Matplotlibはデータを見える化する際に使用するライブラリです。データの特徴を認識するとともに、データ自体が信用するに足るのか、データにおかしなところがないかなどデータ全体を俯瞰するのはデータ分析の基本です。
以下にデータ分析時に覚えておくべき使用方法を示します。
import
import matplotlib.pyplot as pltMatplotlibはpyplotを「plt」の名前で呼び出すことが多いので、この形で覚えておきましょう。
bar:棒グラフ
plt.bar(['a', 'b', 'c', 'd', 'e', 'f'], array.flatten())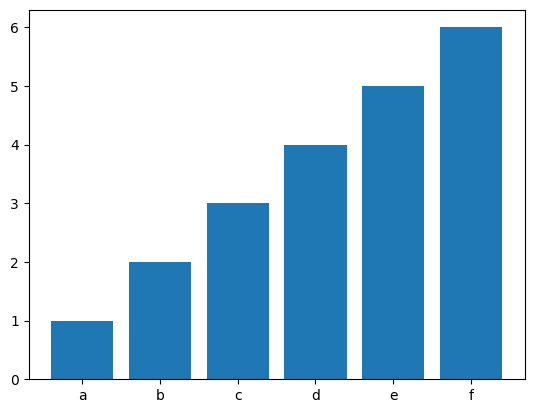
「plt.bar()」で棒グラフを書くことができます。引数一つ目にx軸、二つ目にy軸を指定します。
scatter:散布図
plt.scatter(array.flatten(), array.flatten())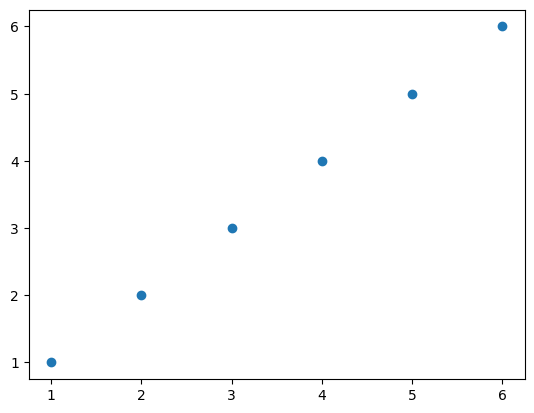
同様に「plt.scatter()」で散布図を書くことができます。引数一つ目にx軸、二つ目にy軸を指定するところは基本同じです。
boxplot:箱ひげ図
plt.boxplot(array.flatten())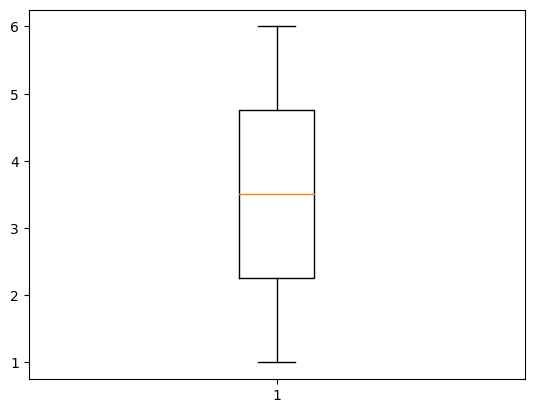
「plt.boxplot()」で箱ひげ図を描くことができます。引数にデータをわたしてやると自動で計算して描画してくれます。
plt.boxplot([[1, 3], [2, 4]])
データを2次元で渡しても自動で描画してくれます。
グラフの装飾
先ほどの散布図を基に基本的なグラフの装飾をしていきましょう。
#グラフのタイトルを表示
plt.title('Scatter')
#X軸ラベル
plt.xlabel('X Label')
#y軸ラベル
plt.ylabel('Y Label')
#「Label」を指定することで「legend」で表示する項目を指定できます。
plt.scatter(array.flatten(), array.flatten(), label='sample')
#同時に別のデータを指定すると重ねて表示ができます。
plt.scatter(array.flatten(), array.flatten()*2, label='sample2')
#データのラベルを表示します
plt.legend()
これで基本的な装飾ができました。このグラフをもとに、必要に応じて装飾してください。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回は、データサイエンス初学者がデータサイエンスで最初に覚えておきたいライブラリを3つ紹介しました。この3つを覚えておけば、Pythonデータ分析を始められます。その際に必要となるものが出てきた際にその都度覚えていきましょう。必要な時に見返してみてください。