9章ではデータサイエンスにおいて必須ともいえるライブラリである『Pandas』の概要と『Series/DataFrame』について解説します。
また、データの概要を把握するのに役立つ『head/tailメソッド』と『describeメソッド』を紹介します。
ぜひ最後まで読んでいってください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
Pandasとは
『Pandas』は、データの分析や前処理をするのに便利なPythonの外部ライブラリです。
データの加工処理を簡単に行うことができるため、データサイエンスや機械学習の分野で頻繁に用いられています。
Pandasの特徴として、『Series』と呼ばれる一次元配列のデータ構造と『DataFrame』と呼ばれる表形式のデータ構造があります。
これらの構造にデータを格納することで、データの集計・抽出・結合などの処理を簡単に行うことができるようになります。
本記事ではSeries/DataFrameの宣言方法およびデータの概要を把握するのに役立つメソッドを紹介します。
Pandasのインポート
それでは早速、Pandasをインポートして使える状態にしていきましょう。
以下のコードを実行して、Pandasをpdという名前でインポートしてください。
import pandas as pdなお、ライブラリの概要やインポートの方法について詳しく知りたい方は、こちらの記事を参照してください。

Seriesの宣言
『Series』は一次元の配列のようなデータ構造で、NumPyのndarrayやPythonのリスト・辞書などから作成することができます。
リスト/配列から作る方法
まずはリストや配列からSeriesを宣言してみましょう。
pd.Series(配列またはリスト, index=(インデックスのリスト))
と書くことでSeriesを作成することができます。
第二引数のインデックスは省略することもできます。
以下の例では、数値が格納されたリストからSeriesを作成しています。
data_s = pd.Series([0,100,200,300,400,500])
print(data_s)0 0
1 100
2 200
3 300
4 400
5 500
dtype: int64右側の数値がデータで、左側の0から始まる数字はSeriesのインデックスです。
インデックスを省略した場合、0から順にインデックスが付けられます。
リストやndarrayと同様に、インデックスを指定することで任意のデータを取り出すことができます。
print(data_s[3])300また、インデックスを指定した場合は以下のようになります。
data_s_idx = pd.Series([100, 150, 500, 100], index=['apple', 'banana', 'grape', 'orange'])
print(data_s_idx)apple 100
banana 150
grape 500
orange 100
dtype: int64辞書と同じように、『values』プロパティと『index』プロパティにより、Seriesの要素とインデックスをそれぞれ取得することができます。
print(data_s_idx.values)
print(data_s_idx.index)[100 150 500 100]
Index(['apple', 'banana', 'grape', 'orange'], dtype='object')辞書から作る方法
続いて辞書からSeriesを作成する方法を説明します。
pd.Series(辞書)
とすることで、辞書のキーをインデックス、値を要素としたSeriesを作成することができます。
#辞書の定義
dic = {'apple':100, 'banana':150, 'grape':500, 'orange':100}
data_s_dic = pd.Series(dic)
print(data_s_dic)apple 100
banana 150
grape 500
orange 100
dtype: int64なお、辞書については以下の記事で詳しく解説しています。
定義の方法からメソッド一覧まで分かりやすく説明していますので、ぜひ参照してください。

DataFrameの宣言
『DataFrame』は表形式のデータ構造で、Seriesと同様にNumPyのndarrayやPythonのリスト・辞書などから作成することができます。
リスト/配列から作る方法
リストからDataFrameを作成する際は、以下のように書きます。
pd.Series(2次元リスト, columns=(列名のリスト))
第一引数にデータとして2次元配列を渡し、引数columnsで各列の名前をリストとして渡します。
まずはリストからDataFrameを作成する例を見てみましょう。
#データ(2次元リスト)
data = [
['John', 28, 'Engineer'],
['Alice', 32, 'Doctor'],
['Bob', 45, 'Teacher']
]
# DataFrameを作成
df = pd.DataFrame(data, columns=['Name', 'Age', 'Occupation'])
df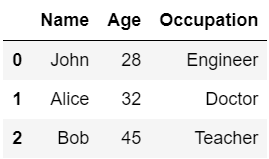
ndarrayを使用しても同じように作成することができます。余裕のある方は試してみると良いでしょう。
辞書から作る方法
値の部分がリストになっている辞書を引数として渡すことでもDataFrameを作成することができます。
#データを辞書で定義
dic = {
'Name':['John','Alice','Bob'],
'Age':[28,32,45],
'Bob':['Engineer','Doctor','Teacher']
}
df = pd.DataFrame(dic)
df辞書を用いてDataFrameを作成する際は、キーが列名、値が要素(データ)に対応します。
また、Seriesと同様に引数indexにリストを渡すことで、インデックスを自分で設定することができます。
#データを辞書で定義
dic = {
'Name':['John','Alice','Bob'],
'Age':[28,32,45],
'Bob':['Engineer','Doctor','Teacher']
}
df = pd.DataFrame(dic, index=['a','b','c'])
df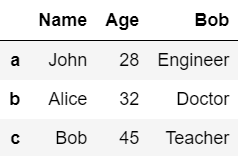
head/tailメソッドでデータの先頭/末尾を表示
headメソッド
『head』メソッドを用いるとDataFrameの先頭の5行を表示することができます。
まずは元となるデータをDataFrameで作成します。
#データ
data = {
'Name': ['John', 'Alice', 'Bob', 'Emily', 'Michael', 'Samantha', 'David'],
'Age': [28, 32, 45, 29, 35, 40, 38],
'Occupation': ['Engineer', 'Doctor', 'Teacher', 'Artist', 'Lawyer', 'Entrepreneur', 'Architect']
}
# DataFramew作成
df = pd.DataFrame(data)
df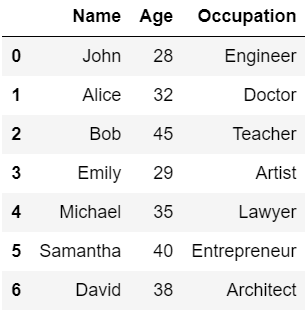
headメソッドを使用して上記のデータの先頭5行を表示してみます。
df.head()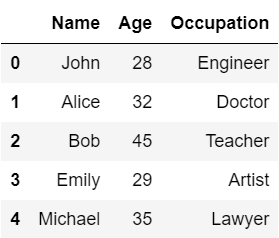
データ数が膨大で、データの先頭だけ表示して概要を確認したいときなどに非常に便利なメソッドです。
tailメソッド
『tail』メソッドはDataFrameの末尾の5行を表示するメソッドです。
headメソッドの説明で使用したDataFrameの末尾5行を表示してみましょう。
df.tail()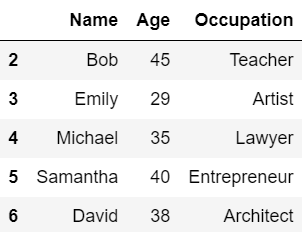
describeメソッドで統計量の一覧を表示
『describe』メソッドを用いると、DataFrameの各列の統計量を一覧として表示することができます。
以下の例を見てみましょう。
#データ
data = {
'Name': ['John', 'Alice', 'Bob', 'Emily', 'Michael', 'Samantha', 'David'],
'Age': [28, 32, 45, 29, 35, 40, 38],
'Occupation': ['Engineer', 'Doctor', 'Teacher', 'Artist', 'Lawyer', 'Entrepreneur', 'Architect'],
'Salary': [60000, 80000, 70000, 50000, 90000, 120000, 100000]
}
#DataFrameを作成
df = pd.DataFrame(data)
df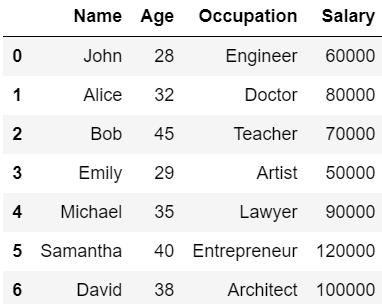
#describeメソッドを使用して統計量を表示
df.describe()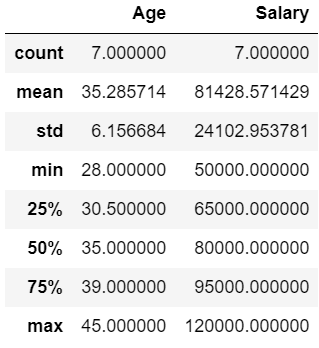
数値を要素として持つ列に対して、各種統計量が表示されているのが分かると思います。
なお、表示される統計量の名前と意味は以下の通りです。
| 統計量の名前 | 意味 |
|---|---|
| count | データの個数 |
| mean | 平均値 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 第一四分位数 |
| 50% | 中央値 |
| 75% | 第三四分位数 |
| max | 最大値 |
統計量の意味がよく分からない・忘れてしまったという方は、以下の記事で詳しく解説していますのでぜひ参照してください!


『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
本記事ではPandasの基本であるSeries、DataFrameの宣言方法およびメソッドを紹介しました。
次章以降でさらに詳しく解説していきますので、本講座でPandasによるデータ操作をマスターしていきましょう!
次のページへ