14章ではPandasのDataFrameにおける『階層型インデックス』について解説しています。
また、『階層型インデックスの作り方』『データの取り出し』『stack/unstackメソッド』について説明しています。
本記事を読めば階層型インデックスを網羅的に理解できます。
ぜひ最後までご覧ください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
階層型インデックスとは
PandasのDataFrameでは、『階層型インデックス(マルチインデックス)』を使用してデータを扱いやすくすることができます。
階層型インデックスは名前の通りインデックスを階層化したものです。
具体例で見てみましょう。
# 階層化された行のインデックスを持つDataFrameを作成する
data = {
'Name':['Taro','Jiro','Saburo','Shiro'],
'Score':['97','90','91','85']
}
index = [['A','A','B','B'], [1,2,1,2]]
df = pd.DataFrame(data, index=index)
df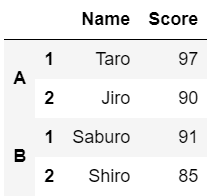
上の例の場合、「Taro, Jiro」の2人がAグループ、「Saburo, Shiro」の2人がBグループに属しており、さらに各グループで「1,2」というラベルが付けられています。
インデックスを階層化することのメリットとして、「データの検索がしやすくなる」、「データの集計がしやすくなる」などが挙げられます。
階層型インデックスの作り方
DataFrameでは行ラベル・列ラベルともに階層化インデックスを定義することができます。
以下で紹介する行ラベル・列ラベルの階層化を組み合わせることで行ラベル・列ラベルの両方を階層化することも可能です。
なお、今回は簡単のため紹介しませんが、「Multiindexオブジェクト」を用いてインデックスを階層化する方法もあります。
気になる方はぜひ調べてみてください。
行ラベルの階層化
DataFrameの定義と同時にインデックスを作成
DataFrameを定義するときに、pd.DataFrameのindex引数に2次元配列を渡すことでインデックスを階層化できます。
# 階層化された行のインデックスを持つDataFrameを作成する
data = {
'Name':['Taro','Jiro','Saburo','Shiro'],
'Score':['97','90','91','85']
}
index = [['A','A','B','B'], [1,2,1,2]]
df = pd.DataFrame(data, index=index)
df2次元配列を用いて各データ(行)に対するインデックスを1つずつ指定することで、インデックスを階層化しています。
また以下のようにすると、階層化されたインデックスに名前を付けることができます。
#インデックスに名前を付ける
df.index.names = ['Class', 'Place']
df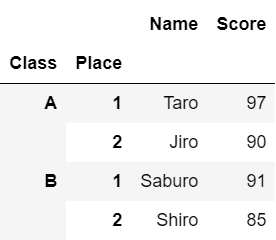
DataFrameの複数の列をインデックスとして指定
既に定義されているDataFrameの列をインデックスとして指定することでも、階層化することができます。
この方法では『set_index』メソッドを使用してインデックスにしたい列を指定します。
まずは、インデックスが指定されていないDataFrameを定義します。
#まず、インデックスを指定せずにDataFrameを作成
data = {
'Class':['A','A','B','B'],
'Place':[1,2,1,2],
'Name':['Taro','Jiro','Saburo','Shiro'],
'Score':['97','90','91','85']
}
df = pd.DataFrame(data)
df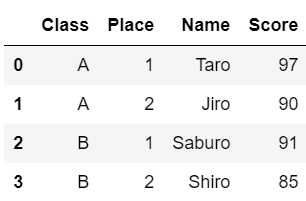
上記の列ラベルから「Class, Place」を選び、この順でインデックスに指定します。
すると、外側からClass, Placeの順に階層化されたインデックスが作成されます。
#複数の列をインデックスに指定すると階層化される
df.set_index(['Class', 'Place'])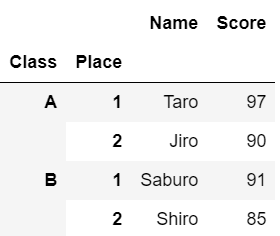
列ラベルの階層化
次に列ラベルを階層化する方法を紹介します。
列ラベルの階層化は、pd.DataFrameのcolumns引数に2次元配列を渡すことで実現できます。
#2次元リストからDataFrameを作成時、引数columnsで列ラベルを指定
data = [
['Taro','Jiro','Saburo','Shiro'],
[97,91,90,85]
]
columns = [['A','A','B','B'], [1,2,1,2]]
df = pd.DataFrame(data, columns=columns)
df
また列ラベルは、DataFrameの元になる辞書においてキーをタプルで指定することで階層化できます。
#辞書からDataFrameを作成時、タプルで各列のインデックスを指定
data = {
('A', 1):['Taro', 97],
('A', 2):['Jiro', 91],
('B', 1):['Saburo', 90],
('B', 2):['Shiro', 85]
}
df = pd.DataFrame(data)
df階層化された列ラベルには、行ラベルの階層化と同様に名前を付けることができます。
#列ラベルに名前を付ける
df.columns.names = ['Class', 'Place']
df
データの取り出し
階層型インデックスを含むDataFrameから特定の範囲のデータを取り出す方法を紹介します。
DataFrameからデータを取り出す基本的な方法については以下の記事で詳しく解説していますので、ぜひ参照しながら読み進めてください。

なお、本記事では簡単のために行ラベルのみが階層化された以下のDataFrameを使用します。
data = {
'Name':['Taro','Jiro','Saburo','Shiro'],
'Score':['97','90','91','85']
}
index = [['A','A','B','B'], [1,2,1,2]]
df = pd.DataFrame(data, index=index)
df.index.names = ['Class', 'Place']
df列ラベルが階層化されている場合も同じようにデータを取り出せるので、余裕のある方は試してみてください。
列名/行名を指定して取り出し
まずはlocやilocを使わずに列名/行名を指定してデータを取り出す方法を説明します。
階層化されていないインデックスの指定方法
今回は列ラベルが階層化されていないので、列の取り出しは通常のDataFrameと同様の方法で行えます。
#Name列のみを取り出す
df['Name']Class Place
A 1 Taro
2 Jiro
B 1 Saburo
2 Shiro階層化されたインデックスの指定方法
一番外側の階層のみを指定してデータを取り出す場合は、通常のDataFrameと同じように取り出すことができます。
#ClassがAのデータのみを取り出す
df['A':'A']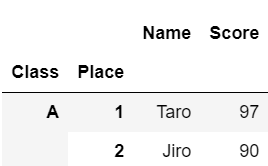
2つ目以降の階層も合わせて指定する場合、タプルを使用します。
#2つ目の階層まで含めて取り出し範囲を指定
df[('A', 2):('B', 1)]
locによる取り出し
一番外側の階層のみを指定する場合は、通常のDataFrameを同じように取り出すことができます。
#ClassがAの行のすべての列を取り出す
df.loc['A', :]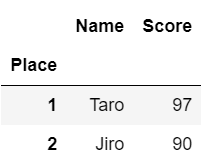
2つ目以降の階層も含めて指定する場合、以下のようにタプルを使用します。
#2つ目の階層まで含めて指定
df.loc[('B', 1), 'Name']'Saburo'複数行を指定する場合、タプルを格納したリストを用いて行を指定します。
#ClassAとBのPlace=2のデータを取り出す
df.loc[[('A', 2), ('B', 2)], :]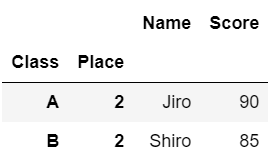
ここで、2つ目以降の階層を指定しつつスライスを行うとエラーが出てしまうことに注意する必要があります。
エラーを回避するためには、『pd.IndexSlice』を以下のように使用します。
#2つ目の階層まで指定してスライス
df.loc[pd.IndexSlice[('A', 2):('B', 2)], :]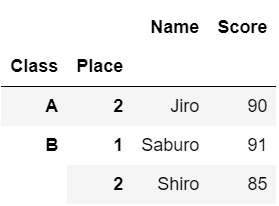
ilocによる取り出し
『iloc』を用いる場合、通常のDataFrameを同様にしてデータを取り出すことができます。
具体例で確認してみましょう。
以下の例では「df」の1行目と3行目のデータから0列目(「Name」列)の値を取り出しています。
#1行目と3行目のデータから0列目を取り出す
df.iloc[[1,3], 0]Class Place
A 2 Jiro
B 2 Shiroまた、以下の例では「df」の1行目から3行目までのデータからすべての列を取り出しています。
#1行目から3行目までのデータからすべての列を取り出す
df.iloc[1:4, :]stack/unstackメソッド
『stack』メソッドや『unstack』メソッドを用いると行を列に、列を行に変更する操作が可能です。
ここでは以下のデータを使用します。
data = {
'Name':['Taro','Jiro','Saburo','Shiro'],
'Score':['97','90','91','85']
}
index = [['A','A','B','B'], [1,2,1,2]]
df = pd.DataFrame(data, index=index)
df.index.names = ['Class', 'Place']
dfstackメソッド
『stack』メソッドを用いると、一番内側の列ラベルが行ラベルに変更されます。
#列ラベルを行ラベルに変更
df.stack()Class Place
A 1 Name Taro
Score 97
2 Name Jiro
Score 90
B 1 Name Saburo
Score 91
2 Name Shiro
Score 85列ラベルだった「Name」と「Score」が行ラベルに変更されているのが分かると思います。
なお、変更後は列ラベルがないためSeriesオブジェクトになります。
unstackメソッド
『unstack』メソッドを用いると、一番内側の行ラベルが列ラベルに変更されます。
#行ラベルを列ラベルに変更
df.unstack()
行ラベルだった「Place」が列ラベルに変更されているのが分かると思います。
すこし見づらいですが、変更後のDataFrameにおいて「Class」は行ラベルの名前で、「Place」は列ラベルの名前です。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
14章の練習問題
以下の練習問題を解いてみましょう。
練習問題
以下のDataFrameを「df」とし、練習問題で使用します。
問1. 以下の問題(1)~(4)に答えてください。
(1) 上記のDataFrame「df」を定義するプログラムを書いてください。
(2) dfのうち「Class」列と「Place」列をインデックスに設定してください。ただし、「Class」列が外側に来るようにしてください。
(3) dfのからClassがBの行のみを取り出してください。
(4) ClassがA、Placeが1に該当するデータのScoreの値を出力してください。
解答
(1)
#(1)
data = {
'Class':['A','A','B','B'],
'Place':[1,2,1,2],
'Name':['Taro','Jiro','Saburo','Shiro'],
'Score':['97','90','91','85']
}
df = pd.DataFrame(data)
df(2)
#(2)
df = df.set_index(['Class', 'Place'])
df(3)
#(3)
df['B':'B']
(4)
#(4)
print(df.loc[('A', 1), 'Score'])97次のページへ