17章ではPandasにおける欠損値の判定方法として『isnull/isnaメソッド』の使い方を紹介します。
また、欠損値の削除・穴埋めに便利な『dropnaメソッド』『fillnaメソッド』『ffill/bfillメソッド』についても解説します。
本記事を読めば、初学者の方も欠損値の処理について実践的に理解することができます。
ぜひ最後まで読んでいってください!
本連載講座【Python ライブラリ編】では、データサイエンスに必要なPythonライブラリやその使い方を基礎から学ぶことができます。
NumPy・Pandas・Matplotlib・Scipy・Seabornについて、初学者の方にも分かりやすいよう丁寧に解説しています。
さらに、学習した内容を定着させられるように各章に演習問題を用意しています。
・Pythonでデータ分析ができるようになりたい
・Pythonの基礎事項は一通り学んだので、さらに深く学びたい
このように考えている方はTech Teacherが運営する【Python ライブラリ編】で、Pythonによるデータサイエンスの学習をすることをお勧めします!
なお、『Pythonについて全く知らない』・『Pythonの基礎事項がまだ分かっていない』という方は、まずコチラの【Python 基礎編】で基礎を一通り学習してからライブラリ編に取り掛かりましょう!
<ライブラリ編 目次>
<ライブラリの基礎>
1章:ライブラリとは
<NumPy>
2章:NumPyの概要と配列(ndarray)
3章:統計量や次元の取得/ソート
4章:配列のインデックス
5章:numpy.whereによる条件制御
6章:配列の結合/分割
7章:乱数
<SciPy>
8章:SciPyの概要と基本操作
<Pandas>
9章:SeriesとDataFrame/統計量の取得
10章:データの読み込み/書き込み
11章:データの取り出し/追加
12章:データのソート
13章:データの結合
14章:階層型インデックス
15章:groupbyによる集計
16章:マッピング処理
17章:欠損値の扱い
<Matplotlib>
18章:Matplotlibの概要
19章:pyplotインターフェース
20章:オブジェクト指向インターフェース
<Seaborn>
21章:Seabornの概要と基本操作

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
欠損値の判定
データ分析の業務で扱うデータなどには多くの場合、値が欠落している部分があります。
そのため、データ分析を学ぶ際には欠損値の判定・処理についてもしっかり理解しておく必要があります。
本記事では欠損値『NaN(Not a Number)』の判定やカウントの方法について解説します。
また、欠損値を削除・穴埋めする方法も紹介します。
まずは事前準備として、NaNを含む適当なDataFrameを準備しましょう。
なお、『np.nan』でNaNを定義することができます。
import numpy as np
#適当なDataFrameを作成
df = pd.DataFrame(np.random.rand(8, 4))
df.columns = ['col0', 'col1', 'col2', 'col3']
df.iloc[1,1] = np.nan
df.iloc[3:, 2:] = np.nan
df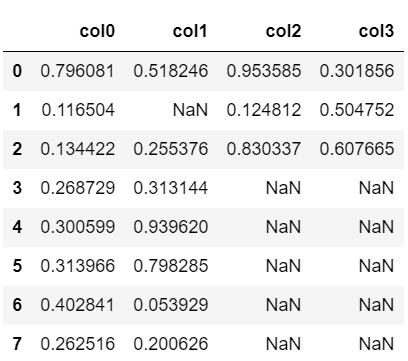
isnull/notnullメソッドで各要素を判定
『isnull』メソッドを用いると、DataFrameの各要素がNaNであるかどうか判定できます。
『isna』メソッドでも同様の判定を行うことができますが、今回はisnullメソッドを使用していきます。
#各要素が欠損値かどうか判定
df.isnull()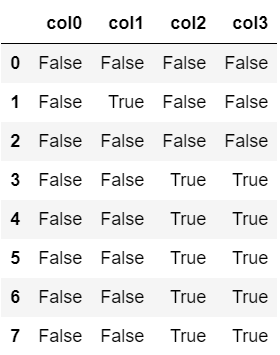
各要素について、NaNの場合はTrueに、そうでない場合はFalseに置き換えられています。
また、『notnull』メソッドを用いるとNaNがFalseに、そうでない要素がTrueに置き換えられます。
df.notnull()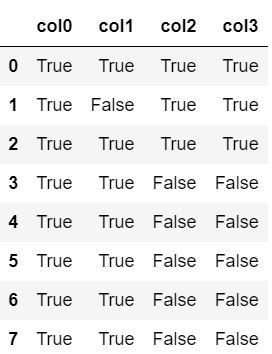
all/anyメソッドで列/行ごとに判定
先ほどの『isnull/notnull』メソッドと『all/any』メソッドを組み合わせて、列/行ごとに欠損値の判定を行うことができます。
all/anyメソッドはNumPyのall/any関数と同じように使用することができます。
NumPyのall/any関数は以下の記事で解説しています。ぜひ参照してください。

以下の例では、isnullの後にanyを用いることでDataFrameの各列に欠損値が存在するかどうかを判定しています。
#欠損値が1つでも存在すればTrue
df.isnull().any()col0 False
col1 True
col2 True
col3 True
dtype: boolまた、all/anyメソッドの引数axisを1にすると、行方向に判定を行うことができます。
#すべての要素が欠損値でない行のみTrue
df.notnull().all(axis=1)0 True
1 False
2 True
3 False
4 False
5 False
6 False
7 False
dtype: bool各列/行の欠損値の数をカウント
『isnull』メソッドと『sum』メソッドを組み合わせることで、各列/行の欠損値の数をカウントすることができます。
『sum』メソッドは、SeriesやDataFrameの列の総和を計算するメソッドです。
真偽値配列に対して用いた場合、Trueは1、Falseは0としてカウントされます。
#各列の欠損値の個数をカウント
df.isnull().sum()col0 0
col1 1
col2 5
col3 5
dtype: int64こちらもaxis=1とすることで行方向にカウントすることができます。
#行方向にカウント
df.isnull().sum(axis=1)0 0
1 1
2 0
3 2
4 2
5 2
6 2
7 2
dtype: int64欠損値の削除・穴埋め
dropnaメソッド:欠損値の削除
『dropna』メソッドを用いると、欠損値を含む列・行を削除することができます。
#欠損値を含む行を削除
df.dropna()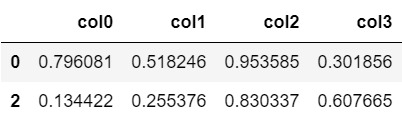
また、引数を指定することによりさまざまな削除の仕方を実現することができます。
本記事では特に引数『axis』『how』の2つについて解説します。
引数axis:削除の対象を列/行から選択
引数『axis』により、行を削除するか、列を削除するかを選択できます。
・axis=0 → 行を削除(デフォルト)
・axis=1 → 列を削除
以下の例では、dropnaメソッドを用いて欠損値を含む列を削除しています。
#欠損値を含む列を削除
df.dropna(axis=1)
引数how:削除の条件を指定
引数『how』により、すべての要素がNaNである場合に削除するか、少なくとも1つの要素がNaNである場合に削除するかを指定できます。
・how=’any’ → 1つでもNaNがあれば削除(デフォルト)
・how=’all’ → すべての要素がNaNなら削除
#すべての要素がNaNの行のみを削除
df.dropna(how='all')今回はすべての要素がNaNである行は存在しないので、要素の削除が行われませんでした。
fillnaメソッド:欠損値の穴埋め
『fillna』メソッドを用いると、欠損値を特定の値で埋めることができます。
すべての要素を特定の値で埋める
fillnaメソッドの引数に特定の値を渡すと、その値で欠損値を穴埋めします。
以下の例では、欠損値NaNを0で埋めています。
#ゼロ埋め
df.fillna(0)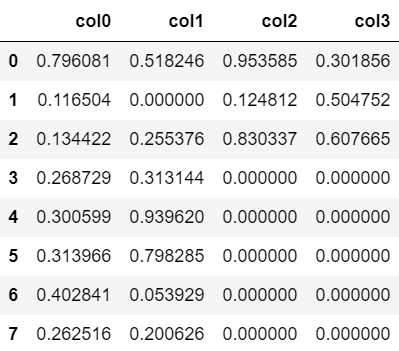
また、平均値で穴埋めを行いたい場合は、以下のように書きます。
#列の平均値で穴埋め
df.fillna(df.mean())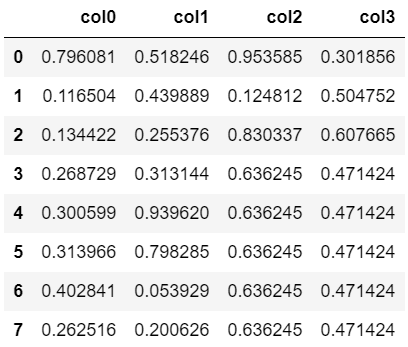
列ごとに特定の値で埋める
列ごとに埋める値を変えたい場合は、fillnaメソッドに辞書を渡します。
以下の例では「col1」列の欠損値は1で、「col2」列の欠損値は2で、「col3」列の欠損値は3でそれぞれ穴埋めを行っています。
#列ごとに埋める値を指定
df.fillna({'col1':1, 'col2':2, 'col3':3})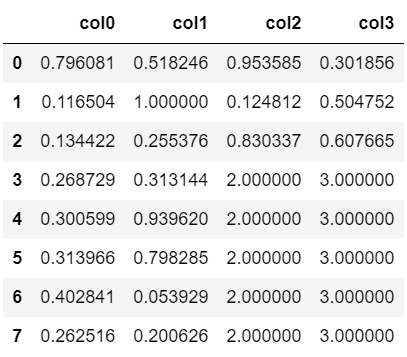
ffill/bfillメソッド:前後の値で穴埋め
『ffill』メソッドや『bfill』メソッドを用いると、それぞれの欠損値の前後の値で穴埋めを行うことができます。
まずはffillメソッドの使用例を見てみましょう。
こちらは前の値で穴埋めを行います。
#前(上)の値で穴埋め
df.ffill()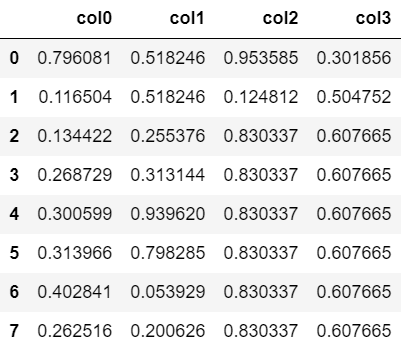
次にbfillメソッドの使用例です。こちらは後ろの値で穴埋めを行います。
#後ろ(下)の値で穴埋め
df.bfill()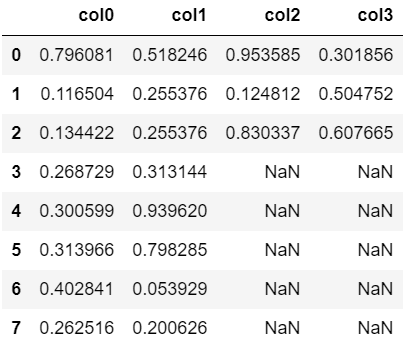

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
17章の練習問題
以下の練習問題を解いてみましょう。
練習問題
問1. 以下のコードで定義されるDataFrame「df」について、(1)~(3)の問いに答えてください。
import numpy as np
df = pd.DataFrame(np.random.rand(8, 4))
df.columns = ['col0', 'col1', 'col2', 'col3']
df.iloc[0, 0] = np.nan
df.iloc[3, 1] = np.nan
df.iloc[2:5, 2] = np.nan
df
(1) dfの各要素について、NaNならTrue、そうでないならFalseで置き換えたDataFrameを出力してください。
(2) dfの各列について、すべての要素がNaNでないかどうかを判定してください。(すべての要素がNaNでない場合にTrueとする。)
(3) dfの各列について、NaNでない要素の個数をカウントしてください。
問2. 問1で使用したdfに対して、(1)~(3)の問いに答えてください。
(1) NaNを含む行をすべて削除したDataFrameを出力してください。
(2) NaNを0で埋めたDataFrameを出力してください。
(3) NaNを前の値で埋めたDataFrameを出力してください。
解答
(1)
#(1)
df.isnull()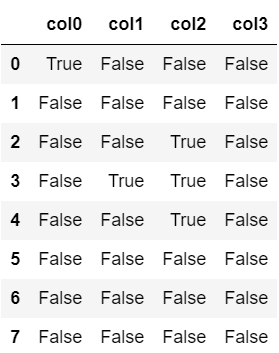
(2)
#(2)
df.notnull().all()col0 False
col1 False
col2 False
col3 True
dtype: bool(3)
#(3)
df.notnull().sum()col0 7
col1 7
col2 5
col3 8
dtype: int64
(1)
#(1)
df.dropna()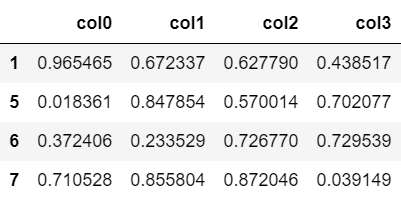
(2)
#(2)
df.fillna(0)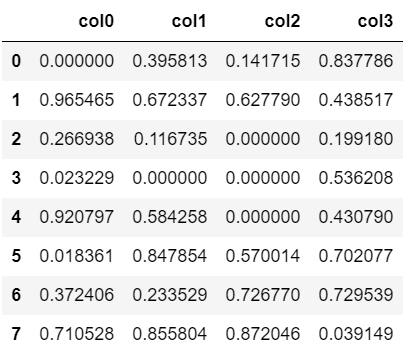
(3)
#(3)
df.ffill()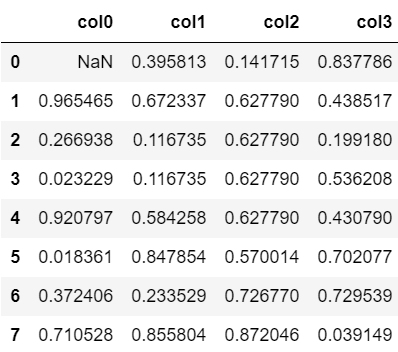
次のページへ