Pythonや機械学習に興味がある方のなかには、下記のように疑問がある方も多いのではないでしょうか。
- Pythonで機械学習ができるって実際何ができるの?
- 機械学習ってそもそも何?
- Pythonで機械学習ができるようになるためにはどうやって勉強すればいい?
本記事では、Pythonでできる機械学習の例や未経験から始める手順をサンプルコード付きで紹介します。Pythonの機械学習に興味がある方や、将来的にデータサイエンスができるようになりたい方は、ぜひ最後までご覧ください!
- 機械学習の種類
- Pythonと機械学習の相性の良さ
- Pythonの機械学習を始めるまでの学ぶべきこと
- Python学習におすすめの本・学習サイト

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
そもそも「機械学習」とは?
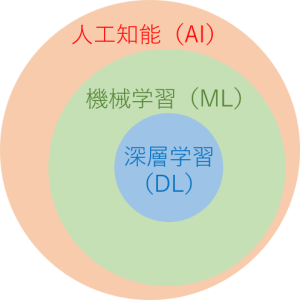
機械学習とは人工知能の技術の1つです。人工知能に大量のデータを与え、自主的に人工知能に学習させることを言います。人工知能と機械学習はイコールではなく、あくまで機械学習は人工知能の一分野となります。
また、機械学習を実現する手法には、深層学習(ディープラーニング)やニュートラルネットワークなどがあります。
人工知能は、データを反復して学習することで人間に近い判断力を持つことができます。ときには人間以上の能力を身につけることができ、人間の代わりに仕事を行う人工知能も現在実用化されています。このように、機械学習は人工知能が発展するための基本技術なのです。
人工知能やディープラーニングについては、こちらの記事で詳しく解説しています!

機械学習の代表的な学習方法
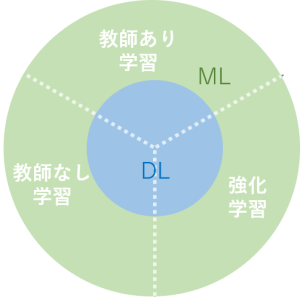
一口に機械学習といっても、いくつか種類があります。ここでは代表的な3つの学習方法を紹介します。
- 教師あり学習
- 教師なし学習
- 強化学習
それぞれの機械学習手法には、向き不向きがあります。そのため自分で開発したい人工知能に、どれが適しているかを分析することが肝心です。では、それぞれの違いを理解していきましょう。
教師あり学習
教師あり学習は、正解をあらかじめ教えた後に学習させる手法です。正しい答えをあらかじめ入力した後に大量のデータを入力し、正解に近いかどうかをコンピュータに判断させます。
たとえば猫の写真を見分けさせたい場合、まず本物の猫の写真を教えます。コンピュータは猫の写真の特徴を分析します。そしてコンピュータにさまざまな写真を入力すると、コンピュータは猫の分析結果と違うものを見分けていきます。
教師あり学習は機械学習の基本と言えるもので、既にさまざまな所で実用化されています。たとえばスパムメールを自動で見分けるツールは、教師あり学習を利用しています。
教師なし学習
教師なし学習は、正解を教えずに学習させる手法です。正解を教えない状態で大量のデータを入力します。コンピュータは自分でデータの特徴やパターンを分析し、グループ分けを行います。
たとえば教師なし学習の1つである「クラスタリング」では、大量のデータ集合の中から共通点やパターンを見つけ出し、共通度が高いグループに分けます。
教師なし学習は、製造現場の異常検知システムでよく使われています。センサーから得られるデータを解析して、機械やシステムのが故障する兆候を検出するのに役立ちます。
なお、教師あり学習と教師なし学習の違いは、下記で詳しく解説していますので参考にしてください!

強化学習
強化学習は、試行錯誤を重ねることによって正解に近づけていく手法のことです。出力結果に点数を付け、点数を高くするために何度も学習を繰り返す、というやり方です。点数を付けることで、それを基準に進化していくことが可能です。
たとえば迷路を解く人工知能を作る場合に強化学習が活用されます。コンピュータは何回も迷路にチャレンジし、何秒でゴールできたか記録をつけていきます。やがて最短経路が分かっていきます。
強化学習は、囲碁・オセロプログラムなどのゲームで活用が進んでいます。
強化学習についてはこちらの記事で詳しく解説しています!

Pythonが機械学習向け言語と言われる理由
Pythonが機械学習に向いている理由は、下記のように機械学習ライブラリが豊富にあるからです。
- scikit-learn
- Tensorflow
- PyTorch
- Chainer
- Keras
ライブラリとは、特定の機能がパッケージとしてまとめられたもののことです。機械学習ライブラリのなかには機械学習の基本となる学習・予測・評価機能が入っており、ライブラリを活用することで効率的に開発ができます。
また、Pythonは学習コストが低いのもメリットです。Pythonは文法が平易ですし、覚えることも少ないです。C言語のポインタのような難しい概念もありません。
Pythonはこういった特徴を持っているため、機械学習に多く使われるのです。なお、機械学習をしたい方が、Pythonを学習するメリットについては、下記で詳しく解説しています。

Pythonのライブラリについては以下の記事で解説しています。

Pythonの機械学習でできること【サンプルコード付き】
機械学習では回帰・分類などの基本的な分析から異常検知、音声認識など、あらゆることができます。Pythonでは機械学習ライブラリや数値演算ライブラリが豊富なため、機械学習を簡単な記述で実装が可能です。今回はさまざまある機械学習のなかで、下記の内容に絞って具体的に紹介します。
- 画像処理
- 自然言語処理
- 時系列分析
これからサンプルコードを見ながら、Pythonでどのようなことができるかを解説します。なお、Pythonの特徴については下記で詳しく解説しているので、参考にしてください。
画像処理
Pythonの機械学習では、画像認識や画像分類などの画像処理も可能です。画像処理の身近な例でいうと、顔認証システムや車両ナンバープレート認識システムが挙げられます。
Pythonには画像データのMNISTや、画像処理の古典的な機械学習モデルが使えるscikit-learnがあるので、簡単に画像処理を行えます。では、手書き文字データの「MNIST」と機械学習ライブラリの「scikit-learn」を使って、Pythonの画像処理を体験してみましょう!
# scikit-learnをインポートする
from sklearn.datasets import fetch_openml
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# MNISTデータをダウンロード
mnist = fetch_openml('mnist_784', version=1)
# 全データを学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, random_state=0)
# サポートベクトルマシンモデルで学習
model = SVC()
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# 正解率で機械学習モデルの精度を評価
print("予測精度:", accuracy_score(y_test, y_pred))
上記のように、人では判別がつきにくい画像データでも、Pythonの機械学習であれば精度高く見分けることが可能です。なお、画像処理に興味がある方は、下記もチェックしてみてくださいね!

自然言語処理
Pythonでは、形態素解析や文脈解析などの自然言語処理も可能です。身近な例では、文章の感情分析やチャットボット制作ができます。
Pythonで自然言語処理を行うには、機械学習ライブラリのscikit-learnに加えて、自然言語処理ライブラリの「MeCab」も必要になる場合があります。MeCabとは、日本語の形態素解析ができるオープンライブラリです。詳しくは下記で紹介しているので、気になる方はチェックしてみてくださいね。

では、指定する日本語がポジティブ(明るい表現)とネガティブ(暗い表現)のどちらかを予測するコードで、Pythonによる自然言語処理を体験してみましょう!
# Numpy・scikit-learn・ランダム関数をインポートする
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import random
# 日本語のポジティブ、ネガティブの文章データを用意
# ポジティブ=1、ネガティブ=0のラベルを付ける
positive_data = [["素晴らしい",1],["最高",1],["大好き",1],["感動した",1]]
negative_data = [["つまらない",0],["ひどい",0],["がっかりした",0],["最悪",0]]
# データを結合してシャッフル
data = positive_data + negative_data
random.shuffle(data)
# 特徴量抽出
vectorizer = CountVectorizer()
features = vectorizer.fit_transform(np.array(data)[:,0].tolist())
# ラベルだけ取り出す
labels = np.array(data)[:,1]
# 全データを学習・テストデータに分割
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2)
# K近傍法で学習
model = KNeighborsClassifier()
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# 予測結果を表示
for i in range(len(y_test)):
print("予測対象データ:", data[i], "機械学習の予測ラベル:", y_pred[i], "予測対象ラベル:", y_test[i])
上記を実行して、「予測対象データ: [‘最高’, 1] 機械学習の予測ラベル: 0 予測対象ラベル: 1予測対象データ: [‘つまらない’, 0] 機械学習の予測ラベル: 0 予測対象ラベル: 1」のような結果が表示されるか確認してみてください。この例のようにPythonを使えば、大量の日本語データでも瞬時に解析できます。
なお、自然言語処理に興味がある方は下記もチェックしてみてください。

時系列分析
Pythonのscikit-learnでは、時系列データの分析も可能です。たとえば、株価の予測や製品の売り上げ予測ができます。では、糖尿病患者の診療データから、1年後の進行状況を予測するコードを見ながら、Pythonの時系列分析を体験してみましょう。
# Numpy・scikit-learnをインポートする
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# 糖尿病患者の診療データを取り込む
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# 糖尿病患者の診療データと進行状況のデータを学習・テストデータに分ける
train_num = -20
diabetes_X_train = diabetes_X[:train_num]
diabetes_X_test = diabetes_X[train_num:]
diabetes_y_train = diabetes_y[:train_num]
diabetes_y_test = diabetes_y[train_num:]
# 線形回帰モデルで学習
linear_model = linear_model.LinearRegression()
linear_model.fit(diabetes_X_train, diabetes_y_train)
# テスト
diabetes_y_pred = linear_model.predict(diabetes_X_test)
# 決定係数で機械学習モデルの精度を評価をする
print("決定係数:", r2_score(diabetes_y_test, diabetes_y_pred))
上記を実行して、「決定係数: 0.58…」などと表示されるか確認してみましょう。
経験豊富な医者でも、1年後の進行状況を予測するのは困難です。一方で上記の例のように機械学習では必要なデータを与えるだけで、数秒程度で時系列データ間の関係性を読みとり予測することが可能です。
なお、時系列分析に興味がある方は、下記もチェックしてみてくださいね!

Pythonの機械学習をゼロから始める手順
本章では、Pythonをプログラミング未経験から機械学習を始めるための手順を紹介します。
- 実行ツールを用意する
- Pythonの基本文法と基本ライブラリの使い方を学ぶ
- 機械学習ライブラリでデータ準備・学習・予測・評価方法を習得する
- サンプルコードを参考に1から機械学習を実装する
それぞれの手順では始め方がイメージできるように、サンプルコードをまとめています。一緒に手を動かしながら、機械学習を始めてみましょう!
実行ツールを用意する
Pythonで機械学習をするためには、まず「実行ツール」を用意する必要があります。さまざまな実行ツールが提供されているなかで、プログラミング未経験者におすすめなのが「Google colaboratory」です。
Google colaboratoryはクラウドの実行ツールなので、難しい環境構築なしですぐに使い始められるメリットがあります。
Google colaboratoryの始め方は、下記のとおりです。
- Google colaboratoryの公式サイトへアクセス
- アカウントを作成(Googleアカウントがある場合には新規アカウント作成が不要)
- ノートブックを新規作成
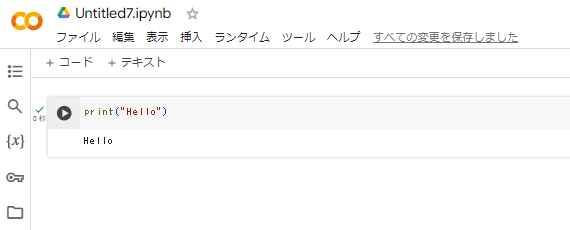
- 表示されるグレーのエディタにコードを書く(おすすめはprint(“Hello”))
- 左側にある「三角矢印を」クリックして実行
- 結果を確認する
4~6の内容は下記画像を参考にしてください。
なお、クラウドの実行ツールではなく、自分のPCにPython用の実行環境を用意したい場合には、下記を見ながら構築しましょう。

Pythonの基本文法と基本ライブラリの使い方を学ぶ
Pythonの機械学習を始める前に、Pythonの基本文法や基本ライブラリを使えるようになりましょう。機械学習では、「forやprint」などのPythonの基本文法を下記のように多用します。
 引用画像:マルチタスク学習の基本から実装までの流れをわかりやすく解説!|Tech Teacher blog
引用画像:マルチタスク学習の基本から実装までの流れをわかりやすく解説!|Tech Teacher blog
また本格的な機械学習をする場合には、コードが長くなります。そのため下記のようにPythonの基本文法である「関数やクラス」を使いこなして、わかりやすいコードを作成する必要があります。
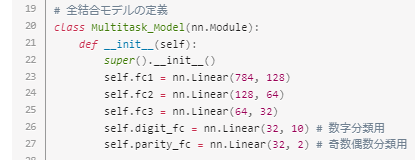
引用画像:マルチタスク学習の基本から実装までの流れをわかりやすく解説!|Tech Teacher blog
そのため基本文法がおろそかになっていると、機械学習のモデルの実行や可視化ができません。まずはPythonの基本文法の種類を理解して、それぞれの文法の適切な利用シーンが自然に思いつき使えるようになるまで勉強しましょう。
基本文法の習得ができたら、Pythonの基本ライブラリを使えるようにしましょう。Pythonで機械学習をするために、最低限習得する必要がある基本ライブラリは下記の3つです。
| ライブラリ名 | 利用シーン |
|---|---|
| NumPy(数値演算ライブラリ) | 機械学習用のデータの前処理・評価など |
| Pandas(表データライブラリ) | データの読み取り・前処理など |
| Matplotlib(画像表示ライブラリ) | データや結果の可視化・グラフ表示 |
各種ライブラリは、データの前処理から機械学習モデルの作成、評価まであらゆるシーンで利用します。たとえば、NumPyの場合には下記のように機械学習モデルや学習誤差を計算する際に使います。

引用画像:【1分でわかる】機械学習の勾配法の概要と仕組みを丁寧に解説|Tech Teacher blog
そのため各種ライブラリでできることを理解し、適切な使い方を調べなくてもある程度頭に出てくるまでインプットしましょう。
各ライブラリの特徴については、下記の記事で詳しく解説しています。

機械学習ライブラリでデータ準備・学習・予測・評価方法を習得する
Pythonの基本的な記述方法がわかれば、「Python機械学習の入門」として機械学習ライブラリの使い方を覚えていきましょう!
機械学習ができるライブラリは「scikit-learn・Tensorflow・PyTorch」など複数ありますが、初心者におすすめなのは「scikit-learn」です。
scikit-learnでは、機械学習モデルや学習・予測に必要なコードが関数になっているため、数行プログラミングするだけですぐに機械学習ができます。ほかのライブラリはオリジナルのモデルを作成できるため良いですが、まずはscikit-learnを習得して「Pythonの機械学習の仕組みや手順」を理解しましょう。
機械学習ライブラリの「scikit-learn」を習得する流れは、下記のとおりです。
- データの準備方法を知る
- 学習・予測方法の書き方を学ぶ
- 評価方法を学ぶ
まず、scikit-learnでデータを準備する方法を理解する必要があります。scikit-learnでは、手書き文字や医療データなど機械学習用のデータをいくつかデフォルトで用意しています。たとえばアイリスと呼ばれる花のデータが集められた「アイリスデータ」を使う場合のサンプルコードは、下記のとおりです。
# アイリスデータをインポート
from sklearn.datasets import load_iris
# アイリスデータを使いやすいように変数に格納
iris = load_iris()
またscikit-learnでは、用意したデータから説明変数と目的変数を指定すれば、学習・予測関数に入れるだけで、結果を自動的に出してくれます。たとえば回帰系の学習と予測の「型」は、下記のとおりです。
# scikit-learnのモデル関数をインポート
from sklearn import linear_model
# 学習モデルの呼び出し(線形回帰モデル)
model = LinearRegression()
# 学習
model.fit(X, y)
# 予測
y_pred = model.predict(X)
# 予測結果を表示
print(y_pred[:10])
学習は「fit関数」へ学習データの目的・説明変数を渡して、予測は「predict関数」にテストデータの目的変数を渡します。scikit-learnを使えば、学習モデルの作成~予測までたった3行程度で実装可能です。
さらにscikit-learnでは、評価まで可能です。たとえば「F値」で評価したい場合には、下記のように記述します。
# F値を計算する関数をインポート
from sklearn.metrics import f1_score
# 予測対象のデータと、予測データを関数に渡す
f1_score(y_true, y_pred)
基本的には、評価関数に予測対象データと予測データを渡すだけで、評価値を算出してくれます。
scikit-learnでは、さまざまな「データセット・学習モデル・評価方法」が用意されています。たとえば学習モデルの場合では「どのような問題を解決したい場合に、どの学習モデルを使えばベターか」といったように、それぞれの違いをコーディングしながら理解するようにしましょう。
なお、scikit-learnについては下記で詳しく解説しているので、参考にしてくださいね!

サンプルコードを参考に1から機械学習を実装する
scikit-learnの使い方がわかれば、実際にサンプルコードを見ながら、Pythonで機械学習のコードを一から作ってみましょう。先述の「できること」で紹介した時系列分析のコードを試しに動かしてみるのがおすすめです。
初めのうちは、サンプルコードを写経することでPythonの機械学習の流れに慣れていきましょう。慣れてきたら、徐々に学習モデルを変えたりオリジナルのデータを使ったりなど、アレンジ箇所を増やしていくことをおすすめします。
一から自分で実装する目的は、これまでに学んできたPythonの基本文法や機械学習ライブラリの内容をアウトプットすることです。最終的には、自作でモデルを実装できるようになるまで、練習を行いましょう!
なお、より深くPythonを知りたい方は、下記をチェックしてくださいね。Pythonの基礎~応用を学ぶ手順を紹介しています。

Pythonによる機械学習を学ぶのにおすすめの本・学習サイト
最後に、機械学習を学ぶうえでおすすめの入門本と学習サイトを紹介します。
- 【Pythonの基礎を無料で学べる】Tech Teacher blog
- 【Pythonの機械学習をコード付きで学べる】スッキリわかるPythonによる機械学習入門
- 【機械学習の数学がわかる】人工知能プログラミングのための数学がわかる本
それぞれの本や学習サイトが、「なぜ必要なのか」「何を習得できるのか」「どのようなスキルを手に入れたい人におすすめなのか」を解説します。Pythonの独学に使う本や学習サイトを迷っている方は、チェックしてみてくださいね!
【Pythonの基礎を無料で学べる】Tech Teacher blog
- Pythonの基礎からしっかりと学びたい人
- プログラミング学習が初めての人
- Pythonの基礎習得にかかる費用を抑えたい人
Pythonの基礎学習には「Tech Teacher blog」がおすすめです!Tech Teacher blogとは、データサイエンスに必要なPythonの基礎やライブラリの使い方を学べる学習サイトです。
ほかの学習サイトでは、Pythonの基礎内容をすべて学習する形式が多く、学び終えるまでに時間がかかります。特に月額で料金がかかる学習サイト場合には、本業などで勉強する時間が取れないと無駄なコストがかかり続けるデメリットがあります。
一方でTech Teacher blogでは、学ぶべき基礎内容が本当に使うものに限定されているので、効率よくPythonを身につけることが可能です。また、無料の学習サイトなので、自分が満足できるまで学べるメリットがあります。
Pythonの機械学習をするためには、基本文法やオブジェクト指向プログラミングの理解が重要です。Tech Teacher blogを通じて、Pythonの機械学習がスムーズに理解できるように土台作りをしましょう。
Pythonの基礎をじっくり時間をかけて学びたい方は、早速下記から始めてくださいね!
【Pythonの機械学習をコード付きで学べる】スッキリわかるPythonによる機械学習入門

- Pythonの基礎を習得した人
- 機械学習ライブラリのなかでもscikit-learnを学びたい人
Pythonの機械学習の基本を学びたい場合には、「スッキリわかるPythonによる機械学習入門」がおすすめです。数式を使った難しい説明が少なく、イラストでサクサクと読み進められるのが特徴です。
また、本書ではPythonの機械学習ライブラリのなかでも「scikit-learn」を使った解説が中心です。scikit-learnのトイデータで回帰や分類、クラスタリングの実装方法を理解できます。
数学の難しい理解が不要でscikit-learnに特化した解説本は、本書くらいです。理論は置いといて、とりあえずscikit-learnの実装ができるようになりたい方は本書を利用しましょう。
- 機械学習によるデータ分析の手順
- 教師あり学習(アヤメの分類・住宅平均価格の予測など)
- 教師なし学習(次元削減・クラスタリング)
- 機械学習の基礎的な数学
- エラー解決方法
- データの前処理の方法
なお、Pythonの習得におすすめの本は、下記でも詳しく解説しています。Python用の参考書を探している方は、チェックしてみてください。

【機械学習の数学がわかる】人工知能プログラミングのための数学がわかる本

- 機械学習を数学的に理解したい人
- 機械学習の中身を理解したい人
- 一から自分で機械学習モデルを実装したい人
機械学習のアルゴリズムや数式を理解したい人には、「人工知能プログラミングのための数学がわかる本」がおすすめです。
機械学習モデルは数学のアルゴリズムに基づいているため、理解して動かすためには数学・統計の知識が必要です。各数学は高校・大学数学レベルまで理解できていると、スムーズです。下記の表にて各数学分野と機械学習の関係性をまとめたので、学習時の参考にしてください。
| 数学分野 | 機械学習での利用シーン |
|---|---|
| 微分 | ・損失関数を求めるとき(予測対象と予測データの誤差を算出する関数) ・ディープラーニング |
| 確率統計 | ・ベイズ/マルコフモデルなど確率モデルを実装するとき ・機械学習モデルの精度を評価するとき ・データの分布を考えるとき |
| 線形代数 | ・ディープラーニング |
数学分野でも「微分・確率統計・線形代数」は特に機械学習との関係性が深く、理解しなければアルゴリズムの内容や学習の過程を理解できません。
「人工知能プログラミングのための数学がわかる本」では、中学で学ぶ「数学の基礎」を解説する項目があるので、段階的に大学レベルの微分・確率統計・線形代数まで習得できます。そのため、特に数学を再学習したい方や、文系数学で止まっている方におすすめの本です。
- 微分の概念と表現方法
- 確率統計(分散・尤度・正規分布)
- 線形代数(ベクトル・行列・線形変換)
- 画像認識や自然言語処理への応用方法

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
Pythonは機械学習を行ううえで最適な言語です。Pythonで機械学習を始める方法は、下記のとおりです。
- 実行ツールを用意する
- Pythonの基本文法と基本ライブラリの使い方を学ぶ
- 機械学習ライブラリでデータ準備・学習・予測・評価方法を習得する
- サンプルコードを参考に1から機械学習を実装する
なお、基本文法と基本ライブラリの学習時には「Tech Teacher blog」がおすすめです!ぜひPythonを使って機械学習を行ってみてくださいね。