

連載講座「0から学ぶ確率統計」では、中学数学の基本的な内容から大学レベルの確率統計を解説しています。
統計やデータサイエンスに興味がある方はぜひご覧ください。
第17章では、「カイ二乗検定」について解説します。
初学者も理解しやすいように丁寧に解説しているので、ぜひ最後までご覧ください。
必要な知識は「区間推定」と「仮説検定」で解説しているので、まだ学習していない方は先にそちらの記事をご覧ください。
本連載講座「0から始める確率・統計講座」では、中学・高校レベルの数学から大学レベルの「確率・統計」を解説しています。
確率・統計を始めて学ぶ方が理解できるよう、丁寧に解説しています。
この講座の内容は「統計検定2級レベルの知識を習得すること」を目標としています。
・中学、高校の数学の内容を覚えてないけど
「確率・統計」を学習したい
・統計検定の対策をしたい
このような考えを持っている方は、Tech Teacherが運営する「0から始める確率・統計講座」を用いて、「確率・統計」の学習をすすめましょう。
<目次>
1章:平均・分散などの基本統計量
2章:相関関係
3章:確率の基本
4章:条件付き確率・ベイズの定理
5章:期待値
6章:代表的な確率分布
7章:母集団と標本
8章:標本平均・不偏分散
9章:中心極限定理
10章:母平均の推定(分散既知)
11章:母平均の推定(分散未知)
12章:仮説検定
13章:正規分布を用いた検定
14章:【t検定】母平均を検定
15章:【F検定】分散に差があるか?
16章:ウェルチの検定
17章:カイ2乗検定
18章:分散分析
19章:回帰分析

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
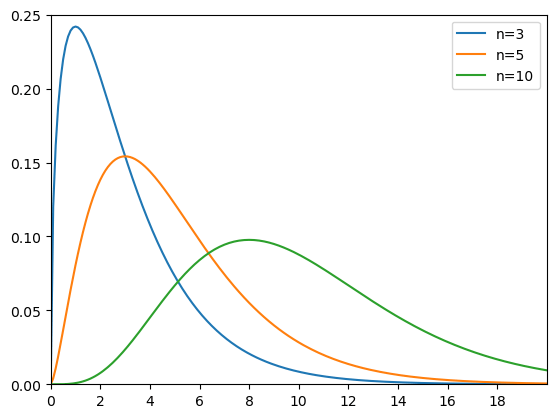
カイ二乗分布とは
本記事では、カイ二乗分布を用いた検定について解説していきます。
カイ二乗分布は以下の確率密度関数で表される確率分布の一種です。
\[ f_n(x) = \begin{cases} \frac{1}{2^{\frac{n}{2}} \Gamma\left(\frac{n}{2}\right)} x^{\frac{n}{2}-1} e^{-\frac{x}{2}} & \text{if } x > 0 \\ 0 & \text{if } x \leq 0 \end{cases} \]
上式は自由度\(n\)の場合の式です。
グラフは以下のようになります。
適合度の検定
まずは適合度の検定について解説します。
適合度の検定では、『あるデータセットが特定の確率分布に適合しているかどうか』を検定します。
例えば、日本全体における血液型の人数比はA型が40%、O型が30%、B型が20%、AB型が10%であると言われています。
ある集団における血液型の人数比がこれに一致(適合)しているかどうかを、カイ二乗分布を用いて検定することができます。
このとき、比較対象となる元の確率分布、すなわち日本全体における血液型の人数比は既知であるということに注意してください。
期待度数・観測度数
検定に必要な用語である『観測度数』と『期待度数』について説明します。
『観測度数』とは、抽出した標本で各カテゴリーに属する個体数のことです。
『期待度数』とは、確率から予想される各カテゴリーの個体数のことです。
例えば血液型の例において、それぞれの用語が表す対象は以下のようになります。
・『観測度数』→あるクラスにおける実際のA型、O型、B型、AB型それぞれの人数
・『期待度数』→日本全体における血液型の人数比から予想される、あるクラスにおけるA型、O型、B型、AB型それぞれの人数
100人のクラスにおいてA型が50人、O型が25人、B型が15人、AB型が10人いた場合、それぞれの値は以下のようになります。

カイ二乗分布に従う変数
母集団において、
・相反な\(n\)個のカテゴリー:\(A_i (1 \leq i \leq n)\)
・標本において各カテゴリーに属する個体数:\(x_i (1 \leq i \leq n)\)
・個体が各カテゴリーに属する確率:\(p_i (1 \leq i \leq n)\)
・標本の大きさ:\(N\)
とします。
\(N\)が十分大きいとき、以下の式で表される\(X\)は自由度\(n-1\)のカイ二乗分布に従います。
$$
X=\frac{(x_1-p_1N)^2}{p_1N}+\frac{(x_2-p_2N)^2}{p_2N}+\cdots+\frac{(x_n-p_nN)^2}{p_nN}
$$
この\(X\)を用いて適合度の検定を行っていきます。
各項において、\(x_i\)が観測度数、\(p_iN\)が期待度数を表すことに注意すると理解しやすいと思います。
適合度の検定の流れ
それでは実際に適合度の検定を行ってみましょう。
問題
ある大学の講義に参加した学生100人を血液型によってグループ分けしたところ、それぞれの人数は以下の通りであった。
A型:50人、O型:25人、B型:15人、AB型:10人
また、日本全体における血液型の人数比はそれぞれ以下の通りである。
A型:40%、O型:30%、B型:20%、AB型:10%
この学生グループの血液型の分布は日本全体の血液型の分布と一致していると言えるか。
なお、有意水準「α = 0.05」とする。
仮説検定は以下の手順で進めます。
仮説検定の手順
- 帰無仮説\(H_0\)、対立仮説\(H_1\)を設定する
- 帰無仮説\(H_0\)を真として、統計量の分布を求める
- 有意水準を決める
- 有意水準と統計量の分布から、棄却域を設定する
- 標本から得られた結果が確率的に起こり得るなら、帰無仮説\(H_0\)を受容・対立仮説\(H_1\)を棄却
- 標本から得られた結果が確率的に起こり得ないなら、帰無仮説\(H_0\)を棄却・対立仮説\(H_1\)を採択
「帰無仮説を真とする」気持ちは
帰無仮説は間違っていると思うけど、その仮説を一旦認めて計算してみるね
→(帰無仮説を棄却し)やっぱり対立仮説が正しかったね
という展開を狙っています。
①:帰無仮説\(H_0\)、対立仮説\(H_1\)を設定する
適合度の検定において、帰無仮説\(H_0\)および対立仮説\(H_1\)はそれぞれ以下のようになります。
- 帰無仮説\(H_0\):各カテゴリーに属する確率は\(P(A_i)=p_i\)である
- 対立仮説\(H_1\):各カテゴリーに属する確率は\(P(A_i)=p_i\)ではない
今回の場合、帰無仮説\(H_0\)は『学生のうちA型、O型、B型、AB型に属する人の割合がそれぞれ40%、30%、20%、10%である』と言い換えることができます。
②:帰無仮説\(H_0\)を真として、統計量の分布を求める
A,O,B,AB型に属する確率をそれぞれ\(p_a\), \(p_o\), \(p_b\), \(p_{ab}\)とします。
帰無仮説を真とするため、\(p_a=0.4\), \(p_o=0.3\), \(p_b=0.2\), \(p_{ab}=0.1\)の元で進めていきます。
先ほど述べた通り、
$$
X=\frac{(x_1-p_1N)^2}{p_1N}+\frac{(x_2-p_2N)^2}{p_2N}+\cdots+\frac{(x_n-p_nN)^2}{p_nN}
$$
で表される\(X\)は自由度3(\(=n-1\))のカイ二乗分布に従うとみなすことができます。
③:有意水準を決める
今回は問題文で、有意水準αが
$$ \alpha = 0.05 $$
と定められています。
実際の業務や研究で行う場合は、データ数や状況に応じて適切に設定しましょう。
④:有意水準と統計量の分布から、棄却域を設定する
適合度の検定の場合、期待度数と観測度数が一致した時\(X=0\)となり、両者のずれが大きいほど\(X\)の値は大きくなります。
よって、片側検定を行うことになります。
自由度3のカイ二乗分布における上側5%の点を調べると、
$$ k=7.81 $$
と分かります。
よって、棄却域は
$$ X \geq 7.81 $$
となります。
⑤:標本から得られた結果が確率的に起こり得るなら、帰無仮説\(H_0\)を受容・対立仮説\(H_1\)を棄却
⑥:標本から得られた結果が確率的に起こり得ないなら、帰無仮説\(H_0\)を棄却・対立仮説\(H_1\)を採択
標本データより、
$$
\begin{align*}
X&=\frac{(x_a-p_aN)^2}{p_aN}+\frac{(x_o-p_oN)^2}{p_oN}+\frac{(x_b-p_bN)^2}{p_bN}+\frac{(x_{ab}-p_{ab}N)^2}{p_{ab}N}
\\ &=\frac{(50-0.4 \cdot 100)^2}{0.4 \cdot 100}+\frac{(25-0.3 \cdot 100)^2}{0.3 \cdot 100}+\frac{(15-0.2 \cdot 100)^2}{0.2 \cdot 100}+\frac{(10-0.1 \cdot 100)^2}{0.1 \cdot 100}
\\ &= 4.583…
\end{align*}
$$
であり、これは7.81より小さい値になっています。
よって帰無仮説を受容し、有意水準5%のもとで
『この学生グループの血液型の分布は日本全体の血液型の分布と一致していないとは言えない』
という結論が得られました。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
独立性の検定
先ほど紹介した適合度の検定を利用して、2つの性質に関する独立性の検定を行うことができます。
分割表とは
独立性の検定を行う際は、『分割表』と呼ばれる表を用いると便利です。
分割表とは、2つの性質におけるカテゴリーごとの個体数を表形式でまとめたものです。

上の例では、『喫煙者か』・『性別』という2つの性質それぞれに2つずつのカテゴリーが存在しています。
適合度の検定の利用
母集団において、
・2つの性質:\(A, B\)
・性質\(A\)における\(m\)個のカテゴリー:\(A_i\) \((1 \leq i \leq m)\)
・性質\(B\)における\(n\)個のカテゴリー:\(B_i\) \((1 \leq i \leq n)\)
・標本の大きさ:\(N\)
とします。
また、カテゴリー\(A_i\)、\(B_j\)に属する確率がそれぞれ\(p_i\)、\(q_j\)であるとします。
このとき性質AとBが独立なら、\(A_i\)かつ\(B_j\)に属する確率は\(p_iq_j\)となります。
よって、\(A_i\)かつ\(B_j\)に属する個体の観測度数を\(x_{ij}\)とすると、
$$ X=\sum_{i=1}^{m} \sum_{j=1}^{n} \frac{(x_{ij}-p_iq_jN)^2}{p_iq_jN} $$
は自由度\(mn-1\)のカイ二乗分布に従います。
これを用いて、2つの性質の独立性を検定することができます。
ただ、実際の検定においては期待度数が不明な場合がほとんどです。
したがって、標本の値から期待度数を推定する必要があります。

上表の\(A_1\)かつ\(B_1\)のセルに注目してください。
このセルに該当する期待度数は\(p_1q_1N\)ですが、このままだと具体的な値が分かりません。
そこで、\(p_1\)を\(a_i\)で、\(q_j\)を\(b_j\)で置き換えることで期待度数を推定します。
\(p_1q_1N=(a_1/N)(b_1/N)N=a_1b_1/N\)
と推定できますね。
これをすべてのセルについて求め、
$$ X=\sum_{i=1}^{m} \sum_{j=1}^{n} \frac{(x_{ij}-a_ib_j/N)^2}{a_ib_j/N} $$
が自由度\((m-1)(n-1)\)のカイ二乗分布に従うことを利用して独立性の検定を行います。
独立性の検定の流れ
それでは実際に独立性の検定を行ってみましょう。
問題
ある集団における男女の人数と喫煙者・非喫煙者の人数はそれぞれ以下の表のとおりであった。この集団において、性別と喫煙状況は独立である(関連がない)と言えるか。
なお、有意水準「α = 0.01」とする。
ここからは一般的な仮説検定と同じ手順で検定を行っていきます。
①:帰無仮説\(H_0\)、対立仮説\(H_1\)を設定する
独立性の検定において、帰無仮説\(H_0\)および対立仮説\(H_1\)はそれぞれ以下のようになります。
- 帰無仮説\(H_0\):2つの性質は独立である
- 対立仮説\(H_1\):2つの性質は独立ではない
今回の場合、帰無仮説\(H_0\)は『性別と喫煙状況は独立である』と言い換えることができます。
②:帰無仮説\(H_0\)を真として、統計量の分布を求める
帰無仮説を真とするため、性別と喫煙状況が独立であるとして進めていきます。
先ほど述べた通り、
$$ X=\sum_{i=1}^{m} \sum_{j=1}^{n} \frac{(x_{ij}-a_ib_j/N)^2}{a_ib_j/N} $$
で表される\(X\)は自由度1(\(=(m-1)(n-1)\))のカイ二乗分布に従うとみなすことができます。
③:有意水準を決める
今回は問題文で、有意水準αが
$$ \alpha = 0.01 $$
と定められています。
実際の業務や研究で行う場合は、データ数や状況に応じて適切に設定しましょう。
④:有意水準と統計量の分布から、棄却域を設定する
独立性の検定の場合、2つの性質が完全に独立であるとき\(X=0\)となり、関連があるほど\(X\)の値は大きくなります。
よって、片側検定を行うことになります。
自由度1のカイ二乗分布における上側1%の点を調べると、
$$ k=6.63 $$
と分かります。
よって、棄却域は
$$ X \geq 6.63 $$
となります。
⑤:標本から得られた結果が確率的に起こり得るなら、帰無仮説\(H_0\)を受容・対立仮説\(H_1\)を棄却
⑥:標本から得られた結果が確率的に起こり得ないなら、帰無仮説\(H_0\)を棄却・対立仮説\(H_1\)を採択
標本データより、
\begin{align*}
X &= \sum_{i=1}^{m} \sum_{j=1}^{n} \frac{(x_{ij}-a_ib_j/N)^2}{a_ib_j/N} \\
&= \frac{(78-170 \cdot 117 / 333)^2}{170 \cdot 117 / 333} +
\frac{(92-170 \cdot 216 / 333)^2}{170 \cdot 216 / 333} +
\frac{(39-163 \cdot 117 / 333)^2}{163 \cdot 117 / 333} +
\frac{(124-163 \cdot 216 / 333)^2}{163 \cdot 216 / 333} \\
&= 17.60\dots
\end{align*}
であり、これは6.63より大きい値になっています。
よって帰無仮説を棄却し、有意水準1%のもとで
『性別と喫煙状況は独立である(関連がない)とは言えない』
という結論が得られました。






