

ChatGPTが有名になったことでTransformerという機械学習モデルも同時に話題になりました。しかし、
Transformerっていったい何?
なにが優秀なの?
どんなモデルなの?
など、疑問に思ったことはありませんか?今回はTransformerについて確認していきましょう。

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
Transformerとは
TransformerはChatGPTにその技術が使われ、ChatGPTが非常に優れたものであったためChatGPTとともに話題になった機械学習モデルです。
Attention Is All You Needという論文で発表されました。今回はこの内容とともに、Transformerは何に優れていて、何ができるようになったのかを見ていきましょう。
結局何がすごいの?
Transformerモデルが優れているのを実感していただくには過去のNLP(Natural Language Processing:自然言語処理)モデルとの比較が不可欠です。
いままでの自然言語処理モデル
もともと自然言語処理モデルは
- 文章を単語にわけ
- 文章の並びをみて
- 単語の関係性を学習する
という方法をとっていました。
そのため、時系列処理を行うためにRNN:Recurrent Neural Networkというアーキテクチャを使用して、文章の並びを理解していました。その後、LSTM:Long Short-Term Memoryなどの技術が導入されましたが、基本的にこの「前から順番に学習する」という方法で学習をしていました。
Transformerによってここがかわった
Transformerの一番大きな進化は、このRNNを使用せずにAttention構造のみでモデルを作成したことです。Attention構造自体はTransformer以前からありましたが、RNNを使用しなくなったことにより「前から順番に学習する」という制約から解き放たれ、単語を順に読み込む必要がなくなり学習速度が各段に上昇しました。
このことにより学習量が格段に増加し、その結果非常に精度のよいモデルができたことはChatGPTでわかると思います。
Transformerのモデルとは?
Transformerモデル
ではそのTransferモデルについて、Attention Is All You Needの内容をもとに確認していきましょう。
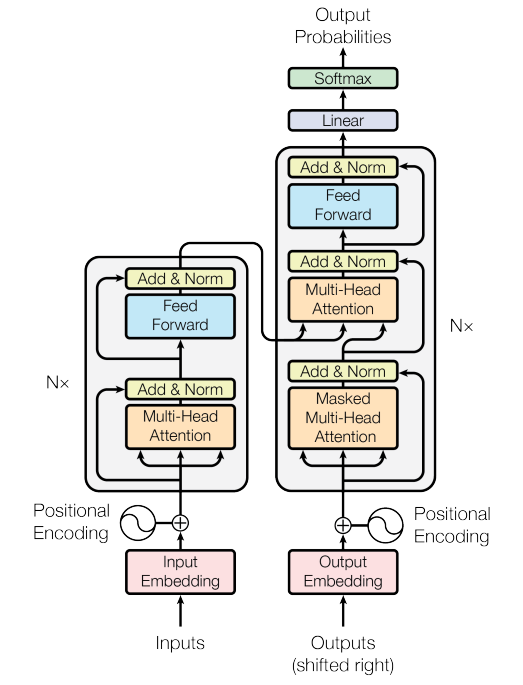
【参考:Biologically Inspired Deep Learning Model for Efficient Foveal-Peripheral Vision】
まず、モデルの構造として特徴的なのは、左側のグレーで囲まれた部分のエンコーダーと、右側のグレーで囲まれた部分のデコーダーからなっている点です。
Attention構造
Transformerの項目でも紹介しましたが、RNNする代わりに使用しているのがAttention構造です。モデルの中では先ほど出てきたエンコーダー、デコーダー間で使われているのがEncoder-Decoder Attention、そして入力文内、出力文内で使用されているのがSelf-Attentionです。モデル内ではこの2つのAttention構造を使用します。
Attention構造は文の中で重要な単語に高いスコアを示します。RNNは時間の近い方、NLPの場合は入力された位置が近い方が関係度の大小に影響していました。NLPにおいては単語の位置が近い方が関連性が高と認識しやすい傾向にありました。
Attention構造になり文章内での位置の近さに関係なく、重要度を取得することができるようになり、さらに精度のよい結果が出るようになりました。
Transformerの応用
Vision Transformer
Transferは注目するところの重要度を数値にして学習していました。これは画像の解析にも活用できそうです。それがVIT:VisionTransferです。
詳しくは「An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale」の中で説明されていますが、NLPの単語に相当する部分に画像の一部分を使用し、Transferと同じように解析するものです。TransferでRNNを使用しなかったように、VITではCNNを使用しません。
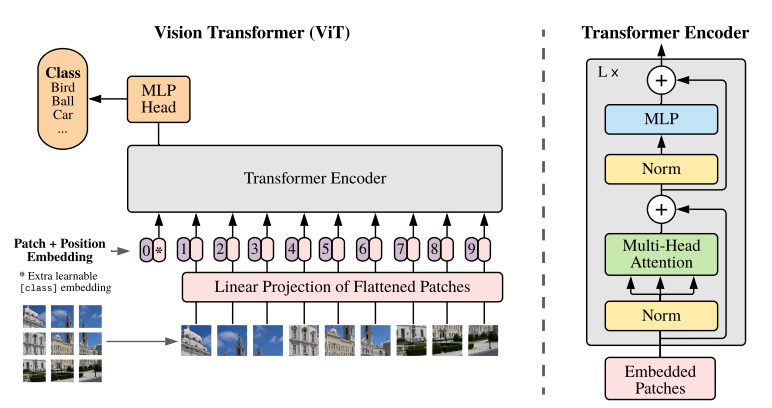
【参考:https://arxiv.org/abs/2010.11929】
このことにより、よい解析精度が出るとともに、CNNで畳み込みを行って特徴をつかみにいかず直接特徴をつかみに行くため、学習時の早期の段階で一般的な特徴をつかみやすいと言われています。
Transformersを使ってみる
さて、そのTransformerですが、Hugging FaceからTransfer周りのモデルを提供するライブラリとしてTransformersが提供されています。今回は2例のみ紹介しますが、Transformersのページに使用方法が乗っていますのでいろいろ使ってみてください。
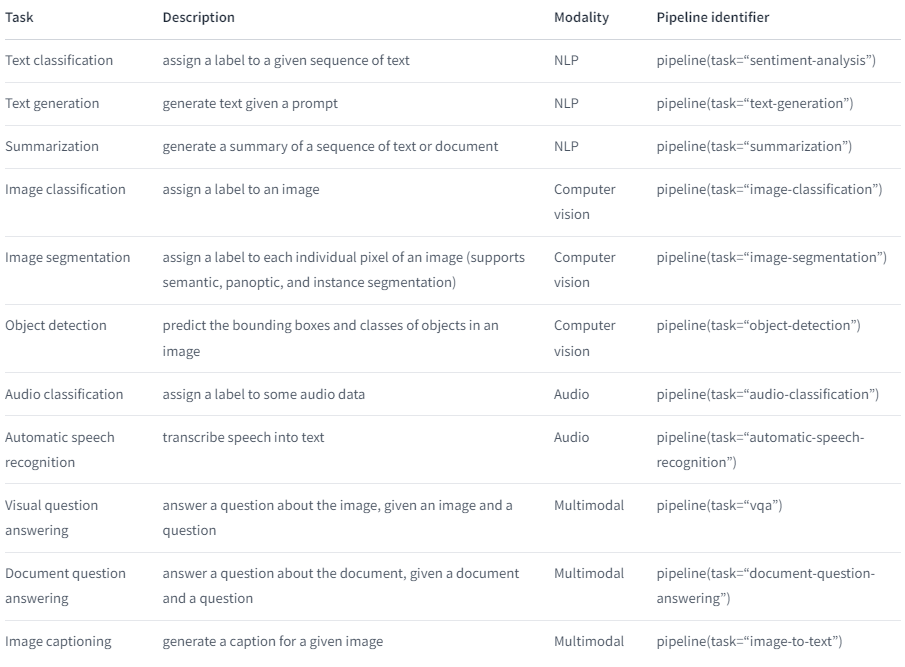
【参考:Hugging Face】
このように、多くのタスクを実施可能なライブラリとして展開されていますが、まずはこの中から一番上にある「sentiment-analysis:感情分析」を試してみましょう。
感情分析
from transformers import pipeline
classifier = pipeline('sentiment-analysis')一行目でライブラリtransformersをインポートします。二行目でclassifireに「sentiment-analysis」をpipelineで渡してやるだけで準備完了です。非常に簡単です。
classifier("We are very happy to show you the 🤗 Transformers library.")
まずはHaggingFaceで紹介されている文から試してみましょう。「トランスフォーマーライブラリーを紹介できてとても幸せです」とのことですね。
結果、POSITIVEほぼ100%ですね。せっかくなので、いくつかのパターンをやってみます。
classifier(["This cake is so delicious", "I think this cake is rotten."])
二つの文章を投げる場合は、上記のようにリストで投げます。「このケーキはとてもおいしい」「このケーキ腐ってると思う」と投げてみました。結果、前者はPOSITIVE、後者はNEGATIVEですね。
classifier(["今日はいい天気です", "熱い", "暑い", "大好きです"])
日本語対応について記述がみられなかったので試してみました。どう見てもNEGATIVEとPOSITEVEが逆のようなので、どうも対応していないようですね。
文章要約
せっかくなので、もう一つタスクをやってみましょう。今度は「summarization:要約」です。
from transformers import pipeline
summarizer = pipeline("summarization")「sentiment-analysis」と使い方は同じです。pipelineに渡してあげます。
summarizer("Get up and running with 🤗 Transformers! Whether you’re a developer or an everyday user,\
this quick tour will help you get started and show you how to use the pipeline() for inference,\
load a pretrained model and preprocessor with an AutoClass, and quickly train a model with PyTorch or TensorFlow.\
If you’re a beginner, we recommend checking out our tutorials or course next for more in-depth explanations of \
the concepts introduced here.")
Hagging faceのクイックツアーの冒頭部分を入れてみました。きれいに要約されています。以下簡単ですが訳を載せておきます。
「このクイック・ツアーでは、推論に pipeline() を使用する方法、事前に学習されたモデルをロードする方法、AutoClass を使用したプリプロセッサを紹介します。初心者の方は、ここで紹介した概念をより深く説明するチュートリアルや次のコースをチェックすることをお勧めします」
データサイエンスを学習するならTech Teacherで!

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
まとめ
今回はTransformerモデルについて確認してきました。本文中でもある通り、ChatGPTの成果もあり、NLPや画像処理において非常に注目されるモデルとなりました。今回の内容でそのTransferモデルを理解していただければと思います。





