

Word2Vec(Word to Vector)とは、単語をベクトルにする自然言語処理分野の技術です。言語をコンピューターで扱う自然言語処理では、単語のような文字列ではなく、ベクトルのような数値列の方が適しています。
本記事ではまず、機械学習の1分野である自然言語処理について紹介します。そして、Word2Vecの概要と具体的なモデルCBOW(Continuous Bag of Words)とSkip-Gramの2つのニューラルネットワークについて解説します。
・自然言語処理の概要
・Word2Vecの概要
・CBOWとSkip-Gramというニューラルネットワークついて

本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
本ブログを運営しているTech Teacherは、
プログラミング家庭教師サービスを運営しています。
完全マンツーマン・フルオーダーメイドで
あなたが必要な指導を提供します。
自然言語処理
自然言語処理とは?
自然言語処理(Natural Language Processing: NLP)とは、人間の言葉をコンピューターで扱うための技術です。
コンピューターで処理するPythonやJavaといったプログラミング言語と区別し、日本語や英語などの人間が日常的に用いる言語を自然言語と呼びます。プログラミング言語は厳格なルールに基づいた一意的な言語ですが、一方、自然言語は時代による意味の変化や新しい単語を生み出す性質を持ち、あいまいな言語と言えます。
うつりゆく自然言語をコンピューターに理解させるためには、その都度、テキストデータから自動で機械に学習させると効率的です。自然言語に利用する目的で収集した大量のテキストデータをコーパスと呼び、コーパスに含まれる単語の意味や文法といった特徴量を自動で抽出する技術としてWord2Vecがあります。
自然言語処理では、単語を数値として処理します。機械学習で扱うデータには、数値や記号などの表でまとめられる構造化データと文章などの非構造化データに分けられます。数値データの場合、何かしらの機械学習モデルにそのまま入力し、出力の傾向や入力の関係性の学習が可能です。
しかし、自然言語処理で扱う非構造化データの場合、そのままでは扱えず、何かしらの数値に変換する処理が必要となります。
自然言語処理の応用
文章分類や文章生成(機械翻訳や質疑応答)などのさまざまなタスクに自然言語処理が応用されています。
Googleの機械翻訳は、ニューラルネットワークを用いて翻訳精度を向上し、OpenAIのChatGPTは、質問に対して人が書いたような自然な文書を返すようになり、自然言語処理分野は近年、特に注目されています。
自然言語処理のさまざまなタスクにおける必須ステップである単語をベクトル化する技術の1種、Word2Vecについて説明します。
以下の記事では自然言語処理の概要、仕組み、利用例を紹介しており、合わせて読むことでより本記事の内容を理解できると思います。

Word2Vec
Word2Vecとは?単語をベクトルにする技術
Word2Vecは、2013年に当時Googleに所属していたTomas Mikolov氏に提案された単語をベクトルにする技術です。
Word2Vecには、文章中の単語の意味は周囲の単語によって形成されるという「分布仮説(Distributional hypothesis)」に基づく方法が用いられています。具体的には、周囲の単語から目的の位置にどのような単語がくるかを予測する問題に分布仮説を帰着させ、ニューラルネットワークを用いて単語をベクトルに変換します。
言語モデルの副産物として得られる単語のベクトル
Word2Vecは、周囲の単語から対象となる単語の出現確率をモデル化した言語モデルの1種です。特に、ニューラルネットワークを用いた言語モデルは、ニューラル言語モデルと呼ばれ、Google翻訳やChatGPTのコアの技術になります。Word2Vecは、言語モデルですが、予測を目的とせず、学習過程の副産物として得られるパラメータから単語のベクトルを獲得します。
Word2Vecで得られる単語の分散表現
Word2Vecで得たベクトルには、単語の意味や文法が反映されます。このベクトルは、単語の分散表現(Distributed Representation)と呼ばれ、各単語がベクトル空間上の点として分散している状態になります。
例えば、ベクトルの次元数が3、つまり、要素が3つの数値列であれば、高さ・幅・奥行の立方体中のどこかの位置に意味や文法を反映した点として単語を表現するということです。
通常、単語の分散表現は、数百次元の実数値の固定長のベクトルとします。自然言語に含まれる何十万もの単語情報をベクトルの次元数に圧縮して固定長にするため、新たに単語を追加しても、ベクトルの次元数を変更せずに済みます。
また、単語の分散表現は、単語をベクトル空間上に埋め込むことから、単語の埋め込み(Word Embedding)とも呼ばれます。Word2Vecでは、単語の分散表現をニューラルネットワークの学習過程で獲得できます。
Word2Vecの学習の仕組み
Word2Vecでは、入力情報を圧縮する過程と単語の予測確率を出力するよう展開する過程の2段階のニューラルネットワークから構成されます。それぞれの過程にモデルのパラメータがあり、コーパスを用いてモデルを学習させ、正しく予測できるようパラメータに更新します。
パラメータには、コーパスに含まれる単語の意味や文法が反映され、単語の分散表現となります。なお、パラメータは2段階の変換過程のそれぞれにありますが、一般的に、入力情報を圧縮するパラメータの方を単語の分散表現として利用します。
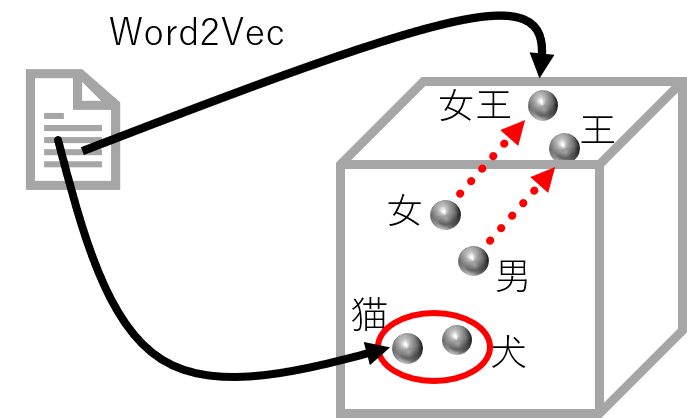
Word2Vecで得られる分散表現では、似た単語は同じようなベクトルになるという類似性があります。例えば、「犬」と「猫」のベクトルの類似度は高くなります。
また、単語の類推も可能になることが知られています。例えば、「王」―「男」+「女」というベクトルの演算をすると、「女王」の単語ベクトルになるという加法性と呼ばれる性質があることが有名です。
つまり、分散表現には、単語の意味だけでなく、単語間の関係性といった特徴も反映します。分散表現の精度は、似た単語同士のベクトルの類似度や「王」の例で挙げた単語間の関係性を類推する問題から評価できます。
CBOWとSkip-Gram
-1024x419.png)
Word2Vecのモデルには、CBOWとSkip-Gramの2種類のニューラルネットワークがあります。
CBOWは周囲の複数の単語から対象の単語を予測し、Skip-Gramは対象となる単語から周囲の複数の単語を予測します。どちらも、コーパスを用いてニューラルネットワークを訓練し、パラメータから分散表現を獲得します。
CBOWでは予測する単語が1つであるのに対して、Skip-Gramでは複数の周辺単語を予測し、学習時に複数単語の予測誤差を計算する必要があるため、計算時間がより長くなります。しかし、多くの場合、Skip-Gramで得た分散表現の方が高い精度になると知られています。
Word2Vecの利活用
日本語の分散表現の獲得
Word2Vecの利用には、PythonのGensimライブラリがあります。Gensimを用いれば、自作のニューラルネットワークを実装せずとも、日本語の文章を単語ごとに分割した単語列を与えるだけで、分散表現を獲得できます。
モデル(CBOWかSkip-Gram)とベクトルの次元数、周囲の単語数(ウィンドウサイズ)などのハイパーパラメータを設定し、集めた興味のあるトピックのコーパスに対して、オリジナルの分散表現が作成可能です。
また、ベクトルの類似度や演算をするメソッドも含まれます。しかし、コーパスが大規模になると、その分、学習時間がかかるため、公開されている学習済みの分散表現を利用するという方法がよく用いられます。公開されている日本語の分散表現をダウンロードすれば、Gemsimで利用でき、後続タスクの開発に時間が割けます。
Word2Vecの利用方法

分散表現が得られれば、ベクトルの類似度や演算などの処理ができるだけでなく、文章分類などの後続タスクに利用できます。分散表現は文章の特徴量を含むため、さらに、ニューラルネットワークやその他の機械学習手法(決定木やサポートベクターマシーンなどの分類器)により文章分類などのタスクへ利用できます。
文章分類の代表例に、文章のポジティブ・ネガティブ判定があります。文章がポジティブな内容かネガティブな内容か判定できれば、自社製品についてコメントしているSNSの大量の文章を収集し、自動で分析が可能となります。例えば、どのようなユーザーがポジティブなコメントをしているのかを分析したり、ネガティブなコメントから製品のフィードバックに利用したりといった応用が期待できます。

『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。
データサイエンスを学習するならTech Teacherで!
『Tech Teacher』3つの魅力
魅力1. オーダーメイドのカリキュラム
『Tech Teacher』では、決められたカリキュラムがなくオーダーメイドでカリキュラムを組んでいます。「質問だけしたい」「相談相手が欲しい」等のご要望も実現できます。
魅力2. 担当教師によるマンツーマン指導
Tech Teacherでは、完全マンツーマン指導で目標達成までサポートします。
東京大学を始めとする難関大学の理系学生・院生・博士の教師がが1対1で、丁寧に指導しています。
そのため、理解できない箇所は何度も分かるまで説明を受けることができます。
魅力3. 3,960円/30分で必要な分だけ受講
Tech Teacherでは、授業を受けた分だけ後払いの「従量課金制」を採用しているので、必要な分だけ授業を受講することができます。また、初期費用は入会金22,000円のみです。一般的なプログラミングスクールとは異なり、多額な初期費用がかからないため、気軽に学習を始めることができます。
まとめ
・魅力1. 担当教師によるマンツーマン指導
・魅力2. オーダーメイドのカリキュラム
・魅力3. 3,960円/30分で必要な分だけ受講
質問のみのお問い合わせも受け付けております。





